RDF(Resource Description Framework;リソース記述フレームワーク)
とは、リソースに関する情報をワールドワイドウェブで表現するための言語であり、特に、表題、著者、Webページの更新日、Web文書の著作権やライセンス情報、共有リソースの有効スケジュールなどのようなWebリソースに関してのメタデータを表現することを目的としている。しかし、「Webリソース」という概念を一般化することによって、RDFは、Webで直接検索できない場合でもWebで識別することのできることについての情報を表現するのにも使用できる。RDFは、Webでの情報を表現するための共通な枠組みを備えているので、意味を喪失することなしにアプリケーション間で情報を交換することができる。
この入門書は、RDFを効果的に使用するのに必要な基礎知識を読者に提供するために考案された。RDFの基本概念を紹介し、そのXMLシンタックス、RDFボキャブラリ記述言語を使用したRDFボキャブラリの定義方法、RDFを導入したアプリケーションの概要について述べている。また、その他のRDF仕様文書の概念と目的についてもふれている。
特に、行った変更が現行の実装やコンテンツにどのように反映されるかについてのフィードバックやコメントの推進のため、本書は、W3Cの会員とその他関連団体のレビュー用に作成された。
本書はW3Cの会員やその他の関連団体によるレビュー用の公的なW3Cの最終ワーキングドラフトである。本節では、発行時の本書の位置づけを述べている。ドラフトの文書のため、本書はいつでも改版、置換、
または他の文書により陳腐化することがある。従って、W3Cのワーキングドラフトを参考文献資料として使用したり、
"進行中の作業"以外のものとして引用することは不適切である。W3Cの提案やその他の技術文書のリストは、http://www.w3.org/TR/で参照できる。
1. 序論
RDF(Resource Description Framework;リソース記述フレームワーク)
とは、リソースに関する情報をワールドワイドウェブで表現するための言語であり、
特に、表題、著者、Webページの更新日、Web文書の著作権やライセンス情報、共有リソースの有効スケジュールなどのようなWebリソースに関してのメタデータを表現することを目的としている。
しかし、「Webリソース」という概念を一般化することによって、RDFは、Webで直接検索できない場合でもWebで識別することのできることについての情報を表現するのにも使用できる。例として、オンラインショッピング機能からの項目(例えば、仕様や価格、可用性など)の情報や、情報発信のためのWebユーザの嗜好の記述などがある。
RDFは、Webでの情報を表現するための共通な枠組みを備えているので、意味を喪失することなしにアプリケーション間で情報を交換することができる。
RDFは共通の枠組みなので、アプリケーション設者は共通のRDFパーサや処理ツールを利用することができる。異なるアプリケーション間で情報交換を行う機能は、つまり、情報はもともとアプリケーション用に作成されるが、そのアプリケーション以外のアプリケーションで情報が利用できると言うことである。
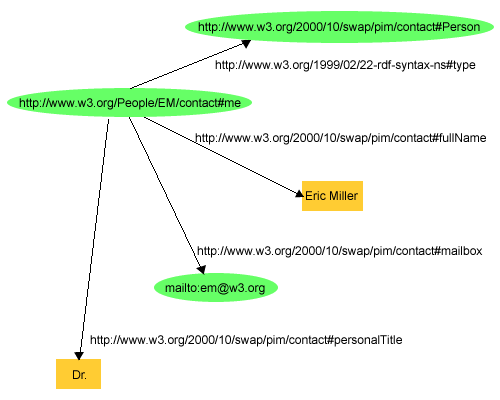
RDFは、Webの識別子(URI)使用して物事を識別するということと、簡単なプロパティやプロパティ値に関してのリソースを表記するという考えに基づいている。この考えによって、RDFは、リソースを表現するノードとアークのグラフや、そのプロパティとプロパティ値として、リソースについての簡単なステートメントを表現できる。できる限り迅速にこの討議を具体的にするために、「メールアドレスが
em@w3.org、役職が博士である、Eric Millerという名前の人がいる。」というステートメントのグループは、図
1のRDFグラフで表すことができる。
図
1では、RDFがURIを使用して以下を特定していることを示している。
- 個人、例えば、Eric Miller、は
http://www.w3.org/People/EM/contact#meで特定される。
- 物事の種類、例えば、人、は
http://www.w3.org/2000/10/swap/pim/contact#Personで特定される。
- メールボックスなどのようなもののプロパティは、
http://www.w3.org/2000/10/swap/pim/contact#mailboxで特定される。
- 上記プロパティの値、例えば、mailboxのプロパティの値としてのmailto:em@w3.org(また、RDFは"Eric Miller"などのように、一部のプロパティの値として文字列を使用する)
さらに、RDFはこういったグラフを記録し、交換するためのXMLベースのシンタックス(RDF/XMLとよばれる)も提供する。例
1 は、図
1のグラフに対応するRDF/XMLのRDFの一部分である。
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:contact="http://www.w3.org/2000/10/swap/pim/contact#">
<contact:Person rdf:about="http://www.w3.org/People/EM/contact#me">
<contact:fullName>Eric Miller</contact:fullName>
<contact:mailbox rdf:resource="mailto:em@w3.org"/>
<contact:personalTitle>Dr.</contact:personalTitle>
</contact:Person>
</rdf:RDF>
mailboxと、(省略形の)fullName
、そしてそれぞれの値em@w3.orgとEric
Millerと同様に、このRDF/XMLにもURIが含まれるということに注意。
HTMLと同様に、このRDF/XMLはマシンが処理でき、URIを使用してWeb中の情報の一部分にリンクできる。しかし、従来のハイパーテキストと違ってRDFのURIはWeb上で直接検索できないもの(例えば、Eric
Millerという人)を含む特定可能なものを参照することができる。結果として、Webページなどのようなものの記述に加え、車、ビジネス、人、ニュース
イベントなどの記述も可能である。さらに、RDFのプロパティ自身、URIがあり、結びついている項目間での関係の種類を正確に識別する。
以下の文書は、RDFの仕様書に役立つ。
本入門書は、RDFへの入門について述べ、現行のRDFのアプリケーションを記述し、情報システムの設計者やアプリケーション開発者がRDFの機能とその使用法を理解するのに役立つことを目的としている。特に、以下の質問に答えることもその目的に含まれる。
- RDF様相は?
- RDFはどんな情報を表現できるのか?
- RDFの情報がどのように作成、アクセス、処理されるのか?
- 現行の情報はどのようにしてRDFと組み合わせられるのか?
本入門書は標準非準拠の文書である。つまり、本書はRDFの最終的な仕様書ではない、ということである。本書の例やその他説明資料は、RDFへの理解を促進するためのものであるが、いつも最終的で、完全な回答を提供するわけではない。最終的で完全な回答については、RDFの標準準拠の対応する部分を参照する必要がある。そのため、標準準拠の仕様書の相当部分のリンクを設けた。
2. リソースについてのステートメントの作成
RDFの目的は、WebページなどのWebリソースについてのステートメントを作成する簡単な方法を提供することである。本節では、RDFがこの機能(この概念を記述する規範となる仕様書はRDF Concepts and Abstract Syntax
[RDF-CONCEPTS]である)を提供する方法の背景となる基本的な考察について述べている。
2.1 基本概念
John
Smithという名前の人が特定のWebページを作成したという事実を述べたいと仮定する。英語でそれを述べる簡単な方法は、以下のように簡単なステートメント形式となる。
http://www.example.org/index.html has a
creator whose value is John Smith
物事のプロパティを記述するために、以下の様に、いくつかのことに名前を付けたり特定する必要があるということを表すため、このステートメント部分に下線を引いた。
- 記述したいことを特定するための方法が必要である。 (この場合、Webページ)
- 記述したいことの特定のプロパティ(この場合、creator(作者))を特定するための方法が必要である。
- 記述したいものに対し、このプロパティの値(creator(作者)は誰か)として割り当てるものを特定するための方法が必要である。
このステートメントでは、WebページのURL(Uniform Resource Locator)
を使用して特定した。また、話題にするプロパティを特定するために「creator(作者)」を使用し、話題にしたい物事(人)を特定するために二語「John
Smith」はこのプロパティの値である。
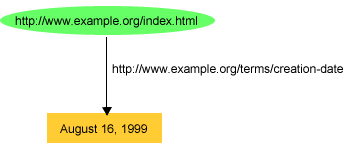
ページを特定するURLとプロパティとその値を特定するための言葉(または、他の表現)を使用して、同じような一般的な形式の英語のステートメントを追加することによって、このWebページの他のプロパティを述べることができる。例えば、ページを作成した日とページが作成された言語を指定するために、以下のステートメントを追加することができる。
http://www.example.org/index.html has a
creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
RDFは、記述するものには値を持つプロパティがあるということと、ステートメントの作成や、上記と同じようなことでリソースが記述できる、ということ、そして、このプロパティと値を指定するという考えに基づいている。RDFは、ステートメントの様々な部分について述べるために特別な用語を使用する。特に、ステートメントが何かということを特定する部分(この例では、Webページ)を主語
(subject)という。ステートメントが明記する主語のプロパティや特徴を特定する部分(この例では、creator、creation-date、や、language)
を述語
(predicate)、プロパティの値を特定する部分を目的語 (object)
という。従って、英語のステートメントは以下になる。
http://www.example.org/index.html has a
creator whose value is John Smith
ステートメントのいろんな部分のRDF用語は以下となっている。
- 主語(subject)はURL http://www.example.org/index.html。
- 述語(predicate) は、「creator」という言葉。
- 目的語(object)は、「John Smith」というフレーズ。
なお、英語は(英語を話す)人での間でコミュニケーションをとるのに便利だが、RDFはマシンが処理できるステートメントを作成しようとしている。マシンが処理するのに適するステートメントを作成するには、以下の二つのことが必要である。
- 他の誰かがWebで使用している可能性のある同じような識別子と混乱することなくステートメント内で主語、述語、目的語を識別できる、マシンが処理できる識別子の仕組み。
- これらのステートメントを表現し、マシン間で交換するためのマシンが処理できる言語。
幸い、現行のWeb構造では必要な機能が備わっている。
これまで見てきたように、Webはすでに、URL
(Uniform Resource Locator)という、一つの識別子の形式を有している。 オリジナルの例を使用してJohn
Smitが作成したWebページ特定する。URLとは、主なアクセスの仕組み(基本的には、そのネットワークの「存在場所」)を表現することによってWebリソースを識別する文字列のことである。Webページとは違って、様々な事柄についての情報を記録したいと考えているため、ネットワークの存在場所やURLを持ってはいない。
こういった目的のため、Webは、Uniform Resource Identifier(URI)という、識別子のより一般的な形式を有している。URLは、URIの特別な種類のことである。URIは、様々な人や組織が物事を識別するために個々に作成し使用することのできるプロパティを共有する。しかし、URIはネットワークの場所を有するもの識別したり、他のコンピュータのアクセスメカニズムを使用することに制限されてはいない。事実、URIを作成して、以下のようなことを含む伝えたいことを参照することができる。
- 電子文書や画像、サービス(例えば「ロスアンゼルスの今日の天気」など)やその他のリソースのグループなどのような、ネットワークでアクセス可能なもの。
- 人や会社、図書館の製本簿などのようなネットワークでアクセスできないもの。
- 「作者」の概念などのような、物理的に存在しない抽象的な概念。
この一般性から、RDFは、主語 (subject)、述語 (predicate)、および目的語 (object)
をステートメント内で識別するためのメカニズムの基礎として、URIを使用する。より正確にするために、RDFはURI 参照 [URIS]を使用する。URI参照
(URIref)は、URIであり、その末尾に任意のフラグメント識別子が付加されている。例えば、URI参照http://www.example.org/index.html#section2は、URI
http://www.example.org/index.htmlと("#"で区切られている )
フラグメント識別子Section2で構成されている。RDFは、リソースをURI参照で識別できるものとして定義するため、URIrefを使用すると、RDFは物事を実質的に記述でき、同時にその物事の間の関係を述べることができる。URIrefとフラグメント識別子に関しては、付録 Aと [RDF-CONCEPTS]で述べる。
RDFステートメントをマシンが処理できる方法で表現するために、RDFはExtensible Markup
Language [XML]を使用する。XMLは、誰もが自身の文書形式を設計し、その形式で文書を書くことができるようにするためにデザインされた。RDF情報を表現する際に使用したり、マシン間で交換したりするために、RDFは、RDF/XMLと呼ばれる特定のXMLマークアップ言語を定義する。RDF/XMLの例は、第1節で述べている。その例(例
1)では、
<contact:fullName>と<contact:personalTitle>などのタグを使用しテキストコンテンツ
Eric
MillerとDr.をそれぞれ区切っている。このようなタグを使用すると、タグの意味を理解して書かれたプログラムはそのコンテンツを適切に解釈できる。
付録
Bでは、一般的なXMLについての背景を詳しく述べている。RDF用に使用される特定のRDF/XMLシンタックスについては、 第3節で取り扱っている。
2.2 RDFモデル
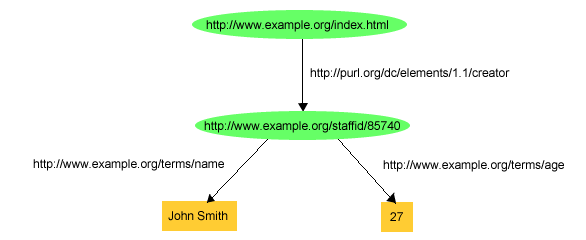
RDFステートメントの基本概念、伝えるものをWeb上で識別するためのURI参照とRDFステートメントを表現するマシンが処理する方法としてのRDF/XML、を紹介したので、URIを使ってRDFでどのようにリソースについてのステートメントを作成できるかについて述べることができる。序論では、RDFはリソースについての簡単なステートメントを表現する考えに基づいており、ステートメントは主語 (subject)、述語 (predicate)、目的語 (object) を使用して構成されている、ということを述べた。RDFでは、オリジナルの英語でのステートメントを以下の様に表現できる。
http://www.example.org/index.html has a
creator whose value is John Smith
RDFステートメントによる表現には、以下が含まれている。
- 主語 (subject)http://www.example.org/index.html
- 述語 (predicate) http://purl.org/dc/elements/1.1/creator
- 目的語 (object) http://www.example.org/staffid/85740
「creator」や「John Smith」のかわりに、オリジナルのステートメントの主語 (subject)だけでなく述語 (predicate)や目的語 (object) を特定するために、どのようにURIrefを使用したかについて注意すること。この件に関しては、本節の後のほうで述べることにする。
RDFは、ステートメントをグラフの中でノードやアークとして表している。RDFのグラフモデルは、[RDF-CONCEPTS]で定義されている。この表記では、ステートメントは以下によって表現される。
- URIrefでラベル付加されている主語 (subject)のノード
- URIrefでラベル付加されている目的語 (object) のノード
- 主語 (subject)ノードや 目的語 (object) ノードから向けられた、URIrefでラベル付加されている述語 (predicate)のアーク
そのため、上記のRDFステートメントは、図
2のグラフで表現される。
ステートメントのグループは対応するノードとアークのグループで表現される。そのため、さらにステートメントを表現する場合は、
http://www.example.org/index.html has a
creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
図
3のグラフで、適応するURIrefを使用して「creation-date」や「language」などのプロパティを指定することができる。
図
3ではRDFステートメントの目的語 (object) が、URIrefで識別されるリソースであるか、または、文字列で表現される(リテラルといわれる)一定の値であるかを示して、ある種のプロパティ値を表現している。リテラルはRDFステートメントの主語
(subject)や述語 (predicate)にはなりえない。(使用している簡潔な文字列のリテラルは現在、型付き(typed)リテラル と区別するために、プレーンなリテラルという。型付き(typed)リテラルについては、第2.4節で紹介する。RDFで使用できる様々なリテラルは、[RDF-CONCEPTS]で定義されている。)
RDFグラフ作成の際、URIrefで識別されるリソースを表現するノードを楕円で示し、リテラルを表現するノードを(リテラル自身でラベル付けされた)箱で示す。
こういったことに関して、グラフを描くのが不便な場合があるので、トリプルというステートメントを書く別の方法も使用される。トリプル表記では、グラフのステートメントはそれぞれ、主語(subject)ノードラベル、述語(predicate)ノードラベル、目的語(object)ノードラベル(URIref
または、リテラル)の順番で、この三つを使った簡単なトリプルで表現される。 図
3 のステートメントを表現するトリプルの全容は以下のようになる。
<http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/creator> <http://www.example.org/staffid/85740> .
<http://www.example.org/index.html> <http://www.example.org/terms/creation-date> "August 16, 1999" .
<http://www.example.org/index.html> <http://www.example.org/terms/language> "English" .
各トリプルはグラフ内で一つのアークに対応し、アークの最初と最後のノード(ステートメントの主語(subject)と目的語(object))を備えている。描いたグラフとは違って(しかし、オリジナルのステートメントと同じ様に)、トリプルの表記には、ノードは表示される各ステートメント様に別々に識別されなければならない。従って、例えば、http://www.example.org/index.htmlはトリプルの中で三回(各トリプルで一回ずつ)表示されるが、描いたグラフには一度しか表示されない。しかし、トリプルはグラフと同じ情報を正確に表現する。このことが重要な点である。つまり、RDFにとって欠かせないものは、ステートメントのグラフモデルであるということである。グラフを表現したり、描いたりするために使用される表記は補助的なものである。
完全なトリプル表記では、上記で示しているように、完全にかぎ括弧に書き込まれたURI参照が非常に長い行となるようにしなければならない。便宜上、本入門書の残りの部分や、他のRDF仕様書でトリプル表記の省略形を使用する。この省略形では、かぎ括弧を使用しない修飾された名前 (QName)を完全なURI参照の省略として代用できる。
QNameには、ネーム空間URIに割り当てられているプリフィックス(接頭辞)が含まれており、その後にコロン、そして、 ローカル名が続く(QNamesは付録 Bで詳しく述べる)。
従って、例えば、QNameプリフィックス(接頭辞)fooがネーム空間URIhttp://example.org/somewhere/に割り当てられている場合、QName
foo:barは、URIrefhttp://example.org/somewhere/barの省略形となる。また、
次に定義されているように、(いつも明示的に指定しなくても使用できる)「周知の」QNameプリフィックス(接頭辞)の例でより広く使用する。
プリフィックス(接頭辞)
rdf:、ネーム空間 URI:
http://www.w3.org/1999/02/22-rdf-syntax-ns#
プリフィックス(接頭辞)
rdfs:、ネーム空間 URI:
http://www.w3.org/2000/01/rdf-schema#
プリフィックス(接頭辞)
dc:、ネーム空間 URI:
http://purl.org/dc/elements/1.1/
プリフィックス(接頭辞)
daml:、 ネーム空間 URI:
http://www.daml.org/2001/03/daml+oil#
プリフィックス(接頭辞)
ex:、ネーム空間 URI:
http://www.example.org/ (または、http://www.example.com/)
プリフィックス(接頭辞)
xsd:、ネーム空間 URI:
http://www.w3.org/2001/XMLSchema#
また、必要であれば、混乱を招かない場合は、プリフィックス(接頭辞)ex: の例に関して変更を行う。例えば、
プリフィックス(接頭辞)exterms:、ネーム空間URI:
http://www.example.org/terms/
(例として出している組織で使用している用語用)、
プリフィックス(接頭辞)exstaff:、ネーム空間URI:
http://www.example.org/staffid/
(例として出している組織のスタッフの識別子用)、
プリフィックス(接頭辞)ex2:、ネーム空間URI:
http://www.domain2.example.org/ (二番目に例として出した組織)、など
この新しい省略形を使用して、以下の様に上記のトリプルのセットを書くことができる。
ex:index.html dc:creator exstaff:85740 .
ex:index.html exterms:creation-date "August 16, 1999" .
ex:index.html exterms:language "English" .
RDFステートメントについて例では、物事を識別するRDFの基礎的な方法としてURIrefを使用する長所について述べている。例えば、この場合「John Smith」という文字列で最初の例にあるWebページの作者を識別する代わりに、作者をURIrefと割り当てる。この場合(作者の社員番号を使用して)http://www.example.org/staffid/85740。 この時のURIrefを使用する利点は、識別がより正確にできるということである。つまり、ページの作者は「John Smith」や 何千人といるJohn Smithという名前の誰かではなく、(URIrefを作成した誰が人この関連を定義したとしても)このURIrefに関連付けられている特定のJohn Smithであるということである。さらに、ページの作者のURIrefがあるので、それは正真正銘のリソースであり、図 4にあるグラフの様に、名前や年齢などといった作者に関する詳細情報を記録することができる。
また、この例では、RDFがRDFステートメントの中でURIrefを述語(predicate)として使用していることも示している。つまり、プロパティを識別するのに「creator」や「name」などのような文字列(または、文字)を使用するのではなく、RDFはURIrefを使用する。いろんな理由から、URIrefsを使用してプロパティを識別することは重要である。まず、URIrefを使用すると、同じ文字列で識別されそうな、別の誰かが使用している可能性のあるプロパティと自分が使用しているプロパティを区別することができる。例えば、
example.orgは誰かのフルネームを示すための文字列リテラルとして書き出された「name」を使用するが、別の誰かは「name」を他の違ったもの(例えば、プログラムテキストの一部分の変数の名前など)を示すものとして表すかもしれない。Web上で「name」をプロパティ識別子として認識するプログラムは、「name」の使用法については区別しなくてもよい。しかし、example.orgが、「name」のプロパティにhttp://www.example.org/terms/nameを書き込み、他の人が
http://www.domain2.example.org/genealogy/terms/nameを自分自身に書き込んだ場合、(プログラムが自動的に別々の意味と判断できなくても)別々のプロパティが関係している事実をそのまま維持することができる。プロパティを識別するのにURIrefを使用することが重要であることのもう一つの理由は、リソース自身をRDFプロパティとして処理できる、ということがある。プロパティはリソースなので、それらに関する決定的な情報を単に、RDFステートメントをプロパティのURIreに主語(subject)として追加することによって、記録することができる。(例えば、example.orgが「name」で何を意味しているかということの英語表記など)
RDFステートメントで、URIrefを主語(subject)、述語(predicate)、目的語(object)として使用すると、伝える概念の理解の共有を反映(作成)し、共有ボキャブラリを開発し、Web上で使用することができる。例えば、トリプルでは、
ex:index.html dc:creator exstaff:85740 .
URIrefとして完全に展開した場合の述語(predicate)dc:creatorは、Dublin
Coreメタデータ属性セット(詳細は第6.1節で述べている)の「creator」属性への明白な参照である。Dublin Coreメタデータ属性セットは、様々な情報を記述するために広く使用されている属性のセットである。 このトリプルの作者は、(http://www.example.org/index.htmlで識別されている )Webページとページの作者(http://www.example.org/staffid/85740で識別される別個の人物)の関係はまさに、http://purl.org/dc/elements/1.1/creatorで識別される概念であるということを効果的に述べている。また、
http://purl.org/dc/elements/1.1/creator
を理解する誰か、または、いずれかのプログラムは、この関係が意味していることを正確にわかる。
もちろん、URIrefがRDFを使用することで問題がすべて解決するわけではない。その理由は、例えば、未だに同じことを参照するのに異なるURIrefを使用することができるからである。しかし、こういった異なるURIrefは共通にアクセス可能な「Web領域」で使用されるという事実は、別々の参照での同等性を識別したり、一般的な参照を使用する方に移行したりするための機会を作り出す。
こういったことから、RDFは、アプリケーションがより簡単に処理できるステートメントを作成する方法を提供するのである。もちろん、アプリケーションは、現在、そういったステートメントを実際には「理解」できないが、理解できるような方法で処理することができる。例えば、あるユーザが本のレビューのためにWeb検索ができ、各本の平均格付けができた場合。そのユーザはその情報をWebに返すことができる。別のWebサイトでは、本の平均格付けのリストを掲載し、「本のランキング、トップ10」というページを作成できる。そこで、格付けに関する共有ボキャブラリの有用性と使用、そして、適用される本を識別するURIrefの共有グループを使用することによって、(さらに貢献がなされるため)個人個人は双方で理解することができ、ますます強力な本に関する「情報ベース」をWebで構築することができる。毎日Webで何千もの主題について作成されている大量の情報にも同じ原理が応用される。
RDFステートメントは情報を記録するための他の多くの形式と似ている。例えば、
- 簡単な記録でのエントリーやデータ処理システムでリソースを記述するカタログリスト。
- 簡単なリレーショナルデータベースの列。
- 正式な論理での簡単な表明。
そして、こういった形式の情報によって、RDFが多くのソースからのデータをまとめるために使用できるようになり、RDFステートメントとして取り扱うことができる。
2.3
構造化されたプロパティ値と空白のノード
記録しなければならないある事についての情報の種類だけが、これまで説明してきた簡単なRDFステートメントの形式で明らかであれば、それは非常に簡単であるかもしれない。しかし、実際の世界でのデータは、少なくとも表面では、ほとんどそれ以上に複雑な構造を必要とする。例えば、オリジナルの例では、Webページが作成された日付をその値としてのプレーンなリテラルで一つのexterms:creation-dateプロパティ と記録したとする。
exterms:creation-dateプロパティの値、月、日、年を別々の情報の部分として示したいと仮定するか、または、John
Smithの個人情報の場合 John Smithの住所を記録したいと仮定してみる。私たちは、John Smithのアドレスをすべてプレーンなリテラルとして以下の様にトリプルで書くことができる。
exstaff:85740 exterms:address "1501 Grant Avenue, Bedford, Massachusetts 01730" .
しかし、Johnの住所をストリート、都市、州、郵便番号の値などの別々のシートで構成されている構造 として記録する場合を仮定してみると?RDFでどうすればいいのだろうか?
(John
Smithの住所などのような)記述したいものの集合をリソースとして考え、新しいリソースについてのステートメントを作成することによって、この構造化された情報をリソースとしてRDFで表現できる。そのため、RDFグラフでは、John Smithの住所を構成要素に分解するため新しいノードを作成してJohn Smithのアドレスの概念を表現し、その概念を新しいURIrefに割り当てて識別を行う。例えば、http://www.example.org/addressid/85740 (略してexaddressid:85740)の場合。 図 5のグラフを作成して、そのノードで(さらにアークとノードを作成する)RDFステートメントを主語(subject)として以下の様に書く。
または、トリプルでは以下の様になる。
exstaff:85740 exterms:address exaddressid:85740 .
exaddressid:85740 exterms:street "1501 Grant Avenue" .
exaddressid:85740 exterms:city "Bedford" .
exaddressid:85740 exterms:state "Massachusetts" .
exaddressid:85740 exterms:Zip "01730" .
この方法を使用すると、構造化された情報をRDFで表現することができるが、Johnの住所などの概念の集合を表現するために「中間の」のURIrefが多く発生する。こういった概念は特定のグラフ外から直接参照する必要はないため、「universal」識別子を必要としない。また、図 5 のステートメントのグループを表現するグラフの作成時には、図 6のグラフのように簡単に作成できるため、「John Smith」の住所を識別するために割り当てているURIrefは実際には必要はない。
完璧なRDFグラフ、図
6では、「John
Smith」の住所という概念を意味するラベルのないノードを使用した。ノード自身はグラフのほかの部分の重要な連結性を提供するため、このラベル付加されていないノード、空白のノードは、URIrefを必要としなくてもグラフ作成時の目的を果たす。(空白のノードは[RDF-MS]では、匿名リソースと呼ばれていた)しかし、このグラフをトリプルとして表現する場合はそのノード用に明示的な識別子の形式がいくつか必要になるかもしれない。これを理解するために、図
6で示しているものに対応するトリプルを書いてみることができる。以下のようなことが得られる。
exstaff:85740 exterms:address ??? .
??? exterms:street "1501 Grant Avenue" .
??? exterms:city "Bedford" .
??? exterms:state "Massachusetts" .
??? exterms:Zip "01730"
???
が空白ノードの存在を示すものを意味する場合。複雑なグラフには複数の空白ノードが含まれるため、グラフのトリプル表現で複数の空白ノードを区別する方法が必要になる。そのためには、_:name形式を持つ空白ノード識別子を使用してトリプルの空白ノードの存在を示す。例えば、この例では、空白ノード識別子_:johnaddress
を使用して空白ノードを参照する。その場合、結果として生じるトリプルは以下のようになる。
exstaff:85740 exterms:address _:johnaddress .
_:johnaddress exterms:street "1501 Grant Avenue" .
_:johnaddress exterms:city "Bedford" .
_:johnaddress exterms:state "Massachusetts" .
_:johnaddress exterms:Zip "01730" .
グラフのトリプル表現では、グラフの別個の空白ノードには空白ノード識別子が与えられている。URIrefやリテラルと違って、空白のノード識別子はRDFグラフの実際の部分とは考えられない(これは、図
6のグラフを参照したり、空白ノードには空白ノード識別子がないということに注意することによって理解できる)。空白のノード識別子は、グラフがトリプル形式で描かれる場合は、グラフで空白ノードを表現するだけの方法でしかない。また、空白ノード識別子は、一つのグラフを表現するトリプル内でのみ意味を持つ(空白ノードを同じだけ持つ異なる二つグラフでは、独自に同じ空白ノード識別子を使用して区別し、同じ空白ノード識別子を持つ異なるグラフからの空白ノードが同じであると考えることは適切ではない。グラフのノードがグラフ外から参照される必要がある場合、URIrefを割り当ててグラフを識別する必要がある。
本節の初めに、話題にするものをリソースとして考え、その新しいリソースについてのステートメントを作成することによって、John Smithの住所など集合構造を表現できると述べた。本例では、RDFの重要な特徴について説明する。その特徴とは、RDFは2項関係(例えば、John Smithとその住所を表現するリテラルとの間の関係など
項)を表現するということである。Johnとその住所の別々の構成要素との関係を表現しようとする場合、Johnとストリート、市、州、電話番号などの構成要素間のn項 (n方向) 関係(この場合n=5)を取り扱っている。RDFでこういった構造を(例えば、住所をストリート、市、州、郵便番号などのサブ構成要素として考えて)直接表現するには、このn方向関係を別々の2項関係に分解する必要がある。空白のノードは、それを行うための方法を提供する。n項関係がある場合は必ず、その関係の主語(subject)として関係しているものを選ぶことができ(この場合、John)、空白ノードを作成して残りの関係(この場合、Johnの住所)を作成できる。そして、関係の中の残りのもの(この例では、市)を空白ノードで表現されている新しいリソースの別々のプロパティとして表現できる。
また、空白ノードはURIを持たないリソースについて正確にステートメントを作成する方法も提供するが、
URIを有するその他のリソースとの関係に関して記述されるリソースについても同じことが言える。例えば、Jane Smithという人についてのステートメントを作成する場合、 mailto:jane@example.orgなどといったその人のE-mailアドレスを元にURIを使用するのが当然のように思われる。しかし、この方法では、問題がある。例えばJane自身(例、Janeの現在の住所)と同様に彼女のメールボックス(例、メールボックスがあるサーバ)についての情報を記録する場合、E-mailアドレスをもとにJaneのURIrefを使用すると何を述べたいのかがわからなくなる。会社のWebページ、例えば、http://www.example.com/を会社自身のURLとして使用する場合、同じ問題がおきる。繰り返すが、会社についてと同様にWebページ(例、誰がいつ作成したか)についても記録する必要があり、http://www.example.com/をその二つの識別子として使用すると何について述べているかがわからなくなる。
根本的な問題は、JaneのメールボックスをJaneの代わりに使用することは実際は正確ではないということである。つまり、JaneとJaneのメールボックスは同じものではないので、これら二つの識別子も同じではいけない。Jane自身がURIを持たない場合、空白ノードはこの状態を正確に模倣する方法を提供する。私たちは、Janeを空白ノードで表現でき、その値としてURIref mailto:jane@example.orgを持つexterms:mailboxプロパティを空白ノードに入力できる。また、以下のトリプルで示しているように、空白のノードに、exterms:Person(タイプについての詳細は次の節で述べる)の値でプロパティを、"Jane Smith"の値でexterms:nameを、提供するその他の記述情報を割り当てて以下のトリプルのようにもできる。
_:jane exterms:mailbox mailto:jane@example.org .
_:jane rdf:type exterms:Person .
_:jane exterms:name "Jane Smith" .
_:jane exterms:empID "23748"
_:jane exterms:age "26" .
これは、実際には、「タイプexterms:Personのリソースがあり、その電子メールボックスはmailto:jane@example.orgで識別され、その名前はJane
Smithである。など」を示している。つまり、空白ノードは、「リソースがある」と読むことができ、主語(subject)として空白ノードを持つステートメントは、そのリソースの特徴についての情報を提供する。
実際には、こういった事例でURIrefではなく空白ノードを使用してもこの種の情報を正確に処理する方法が変わるわけではない。例えば、(特に、アドレスが再利用さる可能性がない場合に)E-mailアドレスが一意にexample.orgである人を識別するということを知っている場合、そのE-mailアドレスがその人のURIでなくても、複数の情報元からその人に関しての情報を関連付けるため事実を使用できる。例えば、E-mailアドレスが一意にexamle.orgのある人を特定することを知っている場合(特に、アドレスが再使用される可能性がない場合)は、そのE-Mailアドレスがその人のURIでなくても、その事実を使用して複数のソースからその人についての情報を関連づけることができる。
例えば、ある本について述べたWebでRDFの別の部分を検索し、著者の連絡先情報をmailto:jane@example.orgと提供しようとする場合、その著者の名前はJane
Smithだと合理的に判断するかもしれない。ポイントは、「本の著者は、mailto:jane@example.orgである」ということを述べることは、「本の著者は、mailto:jane@example.orgというメールボックスを持つ誰かのことである」ということの短縮形である。空白ノードを使用してこの「誰か」を表現することは、現実世界の状態を表現するより正確な方法なのである。(偶然にもRDFベースのスキーマ言語を使用すると、あるプロパティが一意の識別子であるということを指定できる。これについては第5.5節で述べる。)
2.4 型付き(Typed)リテラル
前節では、プレーンなリテラルで表現されているプロパティ値をとる必要がある場合への対処法とこれらのプロパティ値の個々の部分を識別する構造化された値にプロパティ値を分解する方法を述べた。例えば、Webページが作成された日付を、その値として一つのプレーンなリテラルで一つのexterms:creation-dateプロパティとして記録するといった方法ではなく、この方法をその値として一つのプレーンなリテラルとして使用すると、月、日、年で構成されている値を構造を情報の別々な部分として表現することができる。しかし、プロパティの値を数字(例えば、year
プロパティや
ageプロパティ)やその他、より特殊な値などにするつもりがあったとしても、今まで私たちは、これらのプレーンな(型付きではない)リテラルでRDFステートメント内で目的語 (object) としての役割を果たす一定の値を表現する習慣に従ってきた。
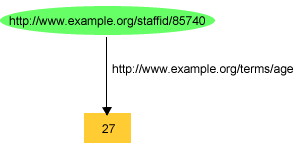
例えば、図
4では、John Smithについての情報を記録しているRDFグラフについて示した。図
7で示しているように、そのグラフでは、John
Smithのexterms:ageプロパティをプレーンなリテラル「27」としてその値を記録した。
この場合、仮の組織、example.orgは、「7」が後に続く「2」という文字で構成された文字列としてではなく、「27」を番号として使用したいと考えている。しかし、リテラル「27」を読み込むアプリケーションは、リテラル「27」が文字を表すいう情報を与えられ、どの番号がリテラル「27」を表す必要があるのかということを理解することになる。プログラミング言語やデータベースシステムで共通の習慣は、データタイプとリテラルを関連づけることによってこの種の情報を提供することである。この場合、データタイプは、decimal
やintegerなど。そして、データタイプを理解するアプリケーションは、例えば、リテラル「10」が数字の10を表すのか、または、、数字2を表すのか、または、「0」が後に続く「1」で構成されている文字列を表すのかは、指定したデータタイプが整数なのか、二進数なのか、文字列なのかで決まる。RDFでは、型付き(typed)リテラルを使用して、この種の情報を提供する。
型付き(typed)リテラルを使用して、 John
Smithの年齢を以下のトリプルを使用して、整数27として記述することができる。
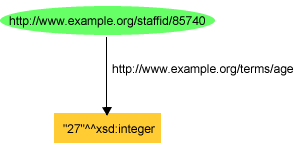
<http://www.example.org/staffid/85740> <http://www.example.org/terms/age> "27"^^<http://www.w3.org/2001/XMLSchema#integer> .
または、長いURIを記述するためのQName仕様を使用して以下の様にもできる。
exstaff:85740 exterms:age "27"^^xsd:integer .
または、図
8の様にもできる。
同じ様に、Webページについての情報を示している図
3のグラフでは、そのページのexterms:creation-dateプロパティの値を「August 16, 1999」で記録した。しかし、型付き(typed)リテラルを使用すると、Webページの作成日をトリプルでAugust 16,
1999と記述することができる。
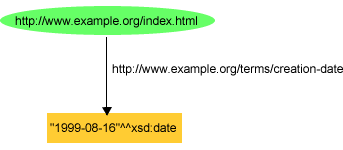
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
または、図
9の様にもできる。
以上の例では、RDFの型付き(typed)リテラルは、特定のデータタイプ(この場合、XML Schema Part 2: Datatypes [XML-SCHEMA2]からのデータタイプ
integerとdate)と表している値を表現するためにデータタイプが使用するリテラルを明示的に組み合わせて形づくられるということを示している。この場合、ラベルとしてその組み合わせを備えているRDFグラフの一つのノードになる。
一般的なプログラミング言語やデータベースシステムと違って、RDFにはそれ自身のデータタイプのセット、例えば、整数、実数、文字列、日付などのデータタイプが組み込まれてはいない。 そのかわり、データタイプ URIで識別できるどこかに定義されているデータタイプに依存する。RDFの型付き(typed)リテラルは、解釈を行うためにどのデータタイプが使用されるべきかを任意のリテラルに対して明示的に示すための方法を示しているだけである。RDFが関係している限り、URIrefとリテラルの一組を型付き(typed)リテラルとして書くことができる。そうすることによって、RDFは異なるソースやRDFデータタイプの元からセット間でタイプの変換を行うことなしに異なるソースからの情報を直接表現できるようになる。(タイプ変換は、異なるデータシステムでシステム間での情報を移動する際に必要であるが、RDFはRDF元来のセットにタイプ変換を行うことはない。)
(表現する値を決定する)型付き(typed)リテラルに関しての実際の解釈は、データタイプを「理解する」ためにプログラムされたRDFプロセッサで行わなければならない。特に、先ほど示した二つの例でXMLスキーマデータタイプを使用し、同様に他の例でもXMLスキーマデータベースを使用するつもりである(例えば、XMLスキーマデータタイプには参照するために使用できるURIrefがある。これは、 [XML-SCHEMA2]で述べている)
。XMLスキーマデータタイプは、RDFでは「第一の」の位置づけがなされており、他のデータタイプと扱いは同じだが、最も広く使用されているため、異なるソフトウエア間でも相互運用ができる可能性が高い。その結果、RDFプロセッサの多くはこれらのタイプを認識するためにプログラムされることになるだろう。しかし、RDFのソフトウエアは同様にデータタイプの他のセットを処理するためにもプログラムできる。
また、RDFデータタイプの概念は、XMLスキーマデータタイプ[XML-SCHEMA2]からの概念的フレームワークを借用してより正確にデータタイプの要件を記述する。このフレームワークのRDFの使用法については、RDF Concepts and Abstract Syntax
[RDF-CONCEPTS]で定義している。
RDFの型付き(typed)リテラルが提供している柔軟性は、かなりの代償となる。例えば、RDFには型付き(typed)リテラルのURIrefが実際にデータタイプを識別しているかどうかを知る方法がない。さらに、URIrefがデータタイプを識別したとしても、RDF自身はそのデータタイプと特定のリテラルの組み合わせの妥当性を定義することはない。この妥当性は、データタイプを理解するために構築されたソフトウェアによってのみ定義できる。例えば、以下のようにトリプルを書くことができる。
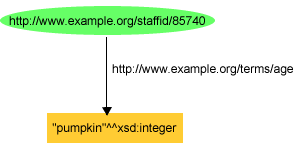
exstaff:85740 exterms:age "pumpkin"^^xsd:integer .
または、図 10の様にもできる。
図
10の型付き(typed)リテラルは有効なRDFであるが、「pumpkin」は
xsd:integerとして合法なリテラルであると定義されていないため、xsd:integerデータタイプが関係する限り、これはエラーである。
一般的に、RDFソフトウェアは理解するためにプログラムされたわけではないデータタイプを含むRDFデータを処理するために必要とされることがある。この場合、ソフトウェアが行うことのできないことがいくつかある。それには、特定の文字列が特定のデータタイプに対し合法な値かどうかを認識することが含まれている。この場合、xsd:integerデータタイプを理解するために構築されたわけではないRDFソフトウェアは、「pumpkin」が有効な
xsd:integerであることを認識することはできない。
3.RDFのXMLシンタックス: RDF/XML
第2節で述べたように、RDFのコンセプチュアルモデルは、グラフである。RDFはRDF/XMLというRDFグラフを作成し、交換するためのXMLシンタックスを提供する。省略形として表されるトリプルと違って、RDF/XMLは、RDFを作成するための標準準拠のシンタックスである。RDF/XMLは、RDF/XML Syntax Specification
[RDF-SYNTAX]で定義されている。本節では、このRDF/XMLシンタックスについて述べる。
紹介している例のいくつかを使用して、RDF/XMLシンタックスの基本構想について説明することができる。最初のステートメントのうちの一つを以下の様に表現すると、
http://www.example.org/index.html has a
creation-date whose value is August 16, 1999
URIrefをcreation-dateプロパティに割り当てた後の一つのRDFグラフは、図 11のようになる。
トリプル表現では、以下の様になる。
ex:index.html exterms:creation-date "August 16, 1999" .
例
2では、図
11のグラフに対応するRDF/XMLシンタックスを示している。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.org/terms/">
4. <rdf:Description rdf:about="http://www.example.org/index.html">
5. <exterms:creation-date>August 16, 1999</exterms:creation-date>
6. </rdf:Description>
7. </rdf:RDF>
(例を説明するのに行番号を付けている。)
これは、オーバーヘッドが大きいように思われる。
かわりにこのXMLの各部分を考慮することによって、何が起こるかをより理解できる(付録
BにXMLへの簡単な紹介を述べている)。
1行目の<?xml
version="1.0"?>は、XML宣言であり、以下のコンテンツはXMLであるということと、XMLのバージョンが何かということを述べているある。
2行目では、rdf:RDF要素を開始している。ここでは以下の(ここから始まり、7行目の</rdf:RDF>で終わる)
XMLコンテンツはRDFを表現することを意味する。同じ行のrdf:RDFの後に続くのは、XMLネーム空間宣言で、rdf:RDFスタートタグのxmlns属性として表現されている。この宣言では、rdf:がプリフィックス(接頭辞)についているこのコンテンツのタグはすべてURIref
http://www.w3.org/1999/02/22-rdf-syntax-ns#で識別されているネーム空間の一部であるということを明記している。このネーム空間は、RDF/XMLで使用されているRDF専用の用語のソースである。
3行目では、別のネーム空間宣言を明記している。この場合は、プリフィックス(接頭辞)exterms:。これは rdf:RDF要素の別のxmlns属性として表現されており、ネーム空間URIref
http://www.example.org/terms/は、exterms:プリフィックス(接頭辞)と関連付けるためのものであると指定している。このネーム空間は、例として使用している組織example.orgのが定義している専用の用語である。3行目の末尾の「>」は
rdf:RDFスタートタグの末尾を示している。1行目から3行目は、XMLコンテンツを定義しているということを示し、使用している用語のソースを識別するのに必要な全般的な「ハウスキーピング」である。
4行目から6行目では、表現している特定のステートメントのRDF/XMLを示している。RDFステートメントについて述べるための明確な方法は、これは、description(記述)であり、ステートメントの主題にabout(ついて)のものであり、
(この場合、http://www.example.org/index.htmlについてのものであり)RDF/XMLがステートメントを表現する方法であるということを述べることである。4行目のrdf:Descriptionスタートタグは、リソースのdescription(記述)を開始するということを示しており、ステートメントが主題のリソースのURIrefを指定するためのrdf:about属性を使用している(ステートメントの主題)について のものであるリソースの特定を続けている。5行目では、タグとしてQName
<exterms:creation-date>でproperty
element(プロパティ要素)を示し、ステートメントの作成日プロパティ、プレーンなリテラル August 19,
1999を維持する。これは、
含有rdf:Description要素内にネストされ、このプロパティはrdf:Description要素のrdf:about属性で指定されているリソースに適用ことを示している。QName
<exterms:creation-date>
に対応する作成日プロパティのURIrefは、http://www.example.org/terms/creation-dateを入力し、名前creation-dateをexterms:プリフィックス(接頭辞)(http://www.example.org/terms/)のURIrefに追加することによって取得される。6行目では、この特定のrdf:Description要素の末尾を示している。
最後に7行目は、2行目で開始したrdf:RDF要素の終了を示す。
例 2では、RDFグラフをXML要素、属性、要素コンテンツ、属性値として符号化するためにRDF/XMLで使用されている基本構造を示している。付録
Bで述べているように、プロパティと目的語 (object) ノードのURIrefラベルは、ネーム空間で修飾した要素や属性を示しているローカル名と一緒に、ネーム空間URIを示す短いプリフィックス(接頭辞)で構成されているXML
QNamesとして書き込まれる。(ネーム空間URIrefとローカル名)一組が選択されるので、これらを結びつけるとオリジナルのノードのURIrefができる。主語 (subject)ノードのURIrefは、XML属性値として書き込まれる。(いつも目的語 (object) ノードとなっている)リテラルでラベル付加されているノードは、要素テキストコンテンツまたは属性値となる。(これらのオプションについては、[RDF-SYNTAX])で述べている。
例
2の4行目から6行目と同じRDF/XMLを使用して各要素を別々に表現することによって、複数のステートメントで構成されているRDFグラフをRDF/XMLで表現することができる。例えば、以下の二つのステートメントを書く場合、
ex:index.html exterms:creation-date "August 16, 1999" .
ex:index.html exterms:language "English" .
RDF/XMLを例
3の様に書くことができる。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.org/terms/">
4. <rdf:Description rdf:about="http://www.example.org/index.html">
5. <exterms:creation-date>August 16, 1999</exterms:creation-date>
6. </rdf:Description>
7. <rdf:Description rdf:about="http://www.example.org/index.html">
8. <exterms:language>English</exterms:language>
9. </rdf:Description>
10. </rdf:RDF>
例
3は、7行目や8行目が追加されているだけで、後は例 2と同じである。二番目のrdf:Description要素は二番目のステートメントを表現するものである。追加のステートメント各々に別々のrdf:Description要素を使用して同じ方法で任意の個数追加したステートメントを表現できる。
例
3で示しているように、XMLネーム空間宣言を書き込む手間に取り掛かると、追加でRDFステートメントをRDF/XMLに書き込むことは、簡単になり、そんなに複雑ではなくなる。
RDF/XMLシンタックスでは、たくさんの省略を提供してより書き込みが簡単にできる共通の使用法とする。 例えば、例
3の様に同じリソースを複数のプロパティや値で同時に記述することは普通である。
この場合、リソースex:index.htmlは複数のステートメントの主語 (subject)である。このような場合に対処するため、RDF/XMLは、これらのプロパティを表現する複数のプロパティ要素を主語 (subject)リソースを識別するrdf:Description要素内にネストすることができる。例えば、
http://www.example.org/index.htmlについて以下のステートメントのグループを書く場合、
ex:index.html dc:creator exstaff:85740 .
ex:index.html exterms:creation-date "August 16, 1999" .
ex:index.html exterms:language "English" .
(図
3と) このグラフは、図
12に示す。
RDF/XMLを例
4の様に書くことができる。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:dc="http://purl.org/dc/elements/1.1/"
4. xmlns:exterms="http://www.example.org/terms/">
5. <rdf:Description rdf:about="http://www.example.org/index.html">
6. <exterms:creation-date>August 16, 1999</exterms:creation-date>
7. <exterms:language>English</exterms:language>
8. <dc:creator rdf:resource="http://www.example.org/staffid/85740"/>
9. </rdf:Description>
10. </rdf:RDF>
前述の2つの例と比べて、例
4では、ネーム空間宣言(3行目)とcreatorプロパティ要素(8行目)が追加されている。また、主語 (subject)がhttp://www.example.org/index.htmlである三つのプロパティのプロパティ要素を一つの
rdf:Description要素にネストした。rdf:Description要素は、各ステートメントに対して
別のrdf:Description要素を書き込むのではなく、その主語 (subject)を認識する。
また、8行目では、プロパティ要素の新しい形式を導入している。(要素タグは、異なるネーム空間プリフィックス(接頭辞)と3行目で定義している新しいネーム空間プリフィックス(接頭辞)dc:も使用する)7行目のexterms:language要素は例
2で定義しているexterms:creation-date要素と似ている。これら二つの要素は、プロパティをプロパティ値としてプレーンなリテラルで表現し、プロパティ名に相当するスタートタグとエンドタグでリテラルを挟むことによって指定される。しかし、8行目のdc:creator要素は、リテラルではなく別のリソースである値をもつプロパティを表現する。他の要素のリテラル値を書いたのと同じ方法で、このリソースのURIrefをスタートタグとエンドタグの間にプレーンなリテラルで書き込んだ場合、dc:creator要素の値は、URIrefとして解釈されているリテラルで認識されたリソースではなく、文字列
http://www.example.org/staffid/85740であるということを述べていることになるだろう。
この相違点を示すため、XMLが空の要素タグ(エンドタグで区切られていない)を呼び出すものを使用してdc:creator要素を書き、空の要素内でrdf:resource属性を使用してプロパティ値を定義した。rdf:resource属性では、プロパティ要素の値が別のリソースであり、URIref自身で識別されるということを示す。RDF/XMLでは、URIrefが属性値として使用されるため、要素と属性名を書く際に行ったようにQNameとしてURIrefを省略するのではなく、URIrefを書き込むことが必要である。
例
4のRDF/XMLは、省略形であるということを理解することが重要である。 各ステートメントが別々に書かれている例
5のRDF/XMLでは、全く同じRDFグラフを記述している。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.org/index.html">
<exterms:creation-date>August 16, 1999</exterms:creation-date>
</rdf:Description>
<rdf:Description rdf:about="http://www.example.org/index.html">
<exterms:language>English</exterms:language>
</rdf:Description>
<rdf:Description rdf:about="http://www.example.org/index.html">
<dc:creator rdf:resource="http://www.example.org/staffid/85740"/>
</rdf:Description>
</rdf:RDF>
次の節では、RDF/XMLの省略形をいくつか記述する。しかし、使用できる省略形の記述の詳細は、[RDF-SYNTAX]を参照する必要がある。
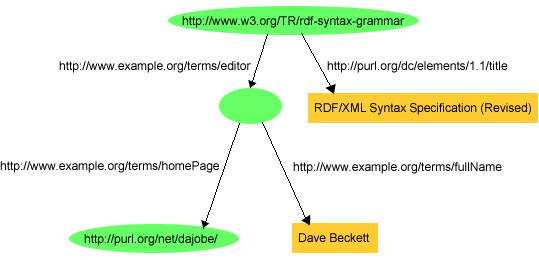
また、RDF/XMLを使用すると、空白のノードなどURIrefsを持たないノードを含むグラフを表現することができる。例えば、図
13(から取り出した[RDF-SYNTAX])では、「文書'http://www.w3.org/TR/rdf-syntax-grammar'のタイトルは'RDF/XML
Syntax Specification (Revised)'で、著者が存在し、その著者の名前は'Dave
Beckett'で、ホームページは'http://purl.org/net/dajobe/'である」というグラフを示している。
この図では、第2.3節で述べた構想を説明している。その構想とは、URIrefがないものを表現するが他の情報に関して記述できる空白のノードの使用法である。この場合、空白のノードは人、文書の編集者が表現され、その人は名前やホームページで記述される。
RDF/XMLは、空白ノードを表現する方法をいくつか提供する。この方法は、[RDF-SYNTAX]で述べる。ここで説明するのは(一番直接的な方法である)空白のノードに空白ノード識別子を割り当てる方法である。空白ノード識別子は、特定のRDF/XMLの文書にある空白ノードを識別する役割をするが、URIrefと違って、割り当てられている文書外では不明である。空白ノードは空白ノード現れる場所以外ではRDF/XMLへ参照できる。特に、主語 (subject)として空白ノードをもつステートメントは、rdf:Description要素を使用して
RDF/XMLに書くことができる。
rdf:Description要素は、rdf:about属性ではなくrdf:nodeID
属性を指定する。同じように空白ノードを目的語 (object) として持つステートメントは、rdf:resource属性ではなくrdf:nodeID属性を持つプロパティ要素を使用して書くことができる。rdf:nodeIDを使用して、例
6では、図
13に対応するRDF/XMLを書く。:
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:dc="http://purl.org/dc/elements/1.1/"
4. xmlns:exterms="http://example.org/stuff/1.0/">
5. <rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
6. <dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
7. <exterms:editor rdf:nodeID="abc"/>
8. </rdf:Description>
9. <rdf:Description rdf:nodeID="abc">
10. <exterms:fullName>Dave Beckett</exterms:fullName>
11. <exterms:homePage rdf:resource="http://purl.org/net/dajobe/"/>
12. </rdf:Description>
13. </rdf:RDF>
例
6では、空白ノード識別子abcが複数のステートメントの主語 (subject)として9行目に、空白ノードはリソースのexterms:editorプロパティの値である、ということを示すために7行目に使用されている。[RDF-SYNTAX]で述べている方法以外のものに関しての空白ノード識別子を使用する利点とは、同じ空白ノードが同じRDF/XML文書内で複数の場所で参照できることである。
最後に、第2.4節で述べた型付き(typed)リテラルは、これまでの例で使用したプレーンなリテラルの替わりのプロパティ値として使用することができる。型付き(typed)リテラルは、データタイプURIrefを指定するrdf:datatype属性をそのリテラルを含むプロパティ要素に付加することによって、RDF/XMLで表現される。
例えば、例
2からステートメントを変更してcreation-dateプロパティのプレーンなリテラルの替わりに型付き(typed)リテラルを使用するには、
トリプルの表現は以下の様になる。
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
のRDF/XMLシンタックスに相当するものは例
7の様になる。:
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.org/terms/">
4. <rdf:Description rdf:about="http://www.example.org/index.html">
5. <exterms:creation-date rdf:datatype=
"http://www.w3.org/2001/XMLSchema#date">1999-08-16
</exterms:creation-date>
6. </rdf:Description>
7. </rdf:RDF>
例
7の5行目では、データタイプを指定するためにrdf:datatype属性を要素のスタートタグに追加することによって、型付き(typed)リテラルは、ex:creation-dateプロパティ要素の値として与えられている。この属性の値はデータタイプのURIrefである。この例の場合、XMLスキーマdateデータタイプのURIref。これは属性値なので、トリプルで使用したQNameの省略形xsd:dateを使用するのではなく、URIrefを書き込まなければならない。そして、このデータタイプに適切なリテラルは要素のコンテンツとして書き込まれる。この例の場合、1999-08-16。これは、XMLスキーマdateデータタイプの1999年8月16日をリテラル表現したものである。
ほとんどの例では、プレーンな
(型付きではない)リテラルの使用を続けているが、XMLスキーマデータタイプなど、適切なデータタイプからの型付き(typed)リテラルはいつもプレーンなリテラルの替わりに使用できるということに注意する必要がある
RDF/XMLを書くための省略形は他にも使用できるが、これまで説明してきた機能はRDF/XMLでグラフをシリアライズするための簡単でより一般的な方法を提供する。この機能を使用して、RDFグラフはRDF/XMLに以下のように書くことができる。
- 空白ノードはすべて空白ノード識別子に割り当てられる。
- ノードはそれぞれ順番にネストされていない
rdf:Description属性の主語 (subject)としてリストされる。ノードにURIrefがある場合はrdf:aboutを使用し、ノードが空白の場合は、rdf:nodeIDを使用する。
主語 (subject)としてノードを持つ各トリプルに対して、リテラル コンテンツ(恐らく空の)か、(目的語 (object) ノードにURIrefがある場合)トリプルの目的語 (object) を指定するrdf:resource属性、か、(目的語 (object) ノードが空白の場合)トリプルの目的語 (object) を指定するrdf:nodeID属性のいずれかを使用して、適切なプロパティ要素が作成される。
[RDF-SYNTAX]で述べているより省略されたシリアライゼーション方法に比べ、このシンプルなシリアライゼーション方法は、実際のグラフ構造のもっとも直接的な表現であり、出力されたRDF/XMLが以降のRDF処理に使用されるアプリケーション様に特に推奨される。
これまで、私達が推測するリソースはすでにURIref与えられているということを述べてきた。例えば、最初の例では、URIrefが
http://www.example.org/index.htmlであるexample.orgのWebページに関する記述的な情報について述べた。完全なURIrefを引用しているrdf:about属性を使用して、このリソースについて触れた。RDFはURIrefがリソースに割り当てられる方法を指定したり、制御したりしないが、URIrefのリソースの組織化されたグループの一部への割り当ての効果を発揮したいと思うときがある。例えば、スポーツ商品の会社example.comがテントやハイキング用のブーツなど自社製品のRDFベースの型カタログをhttp://www.example.com/2002/04/productsで認識される(にある)RDF/XML文書として提供したがっているということを想定する
。そのリソースでは、各製品は別のRDFに与えられる。これらの記述と一緒に、このカタログ、「Overnighter」というテントの型のカタログエントリ、は、例
8で示すようにRDF/XMLで書くことができる。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.com/terms/">
4. <rdf:Description rdf:ID="item10245">
5. <exterms:model>Overnighter</exterms:model>
6. <exterms:sleeps>2</exterms:sleeps>
7. <exterms:weight>2.4</exterms:weight>
8. <exterms:packedSize>14x56</exterms:packedSize>
9. </rdf:Description>
...other product descriptions...
10. </rdf:RDF>
(1行目から3行目、そして、10行目には周囲のxml、RDF、そしてネーム空間の情報が含まれているが、この情報は全カタログ中では一度定義すればよい。カタログの各エントリごとに繰り返し定義しなくてよい。)
例
8は、記述されるリソース(テント)のプロパティ(型、寝るスペース、重さ)を表現する方法において、前回説明した例と似ている。
しかし、4行目では、rdf:Description要素には、rdf:about属性ではなく、rdf:ID属性がある。rdf:IDを使用すると、rdf:ID属性の値で与えられたフラグメント識別子が、記述されているリソースの完全なURIrefの省略形として使用されているということを示すことになる(この場合、item10245。これはexample.comで割り当てられているカタログ番号である)。フラグメント識別子item10245は、基本
URIに関連して解釈される。この場合、含んでいるカタログのURI。テントに関しての完全なURIrefは、(カタログの)基本URIを取り、(後に続くのはフラグメント識別子であると述べるために)#とその後にitem10245を追加し、絶対URIref http://www.example.com/2002/04/products#item10245を与えることによって形成される。
rdf:ID属性は、XMLやHTMLのID属性と幾分か似ている。この中では、定義されている文書(この場合、カタログ)内で一意でなければならないということを定義している。この場合、rdf:ID属性は、名前(item10245)をテントの特定の種類に割り当てられているように見える。このカタログ内の他のRDF/XMLは、rdf:about内の相対URIref
#item10245を使用してテントを参照できる。これは、カタログの基本URIrefに相対する定義されたURIrefであると認識される。
同じ省略形を使用して、
カタログエントリ内(例えば、相対URIrefを直接指定することによって)にrdf:ID="item10245"ではなく、rdf:about="#item10245"を指定することによって、テントのURIrefを与えることができたかもしれない。この二つの方法は、基本的には同義語である。つまり、どちら場合でもRDF/XMLで作成する完全なURIrefは同じhttp://www.example.com/2002/04/products#item10245である、ということである。どちらの場合でも、example.comは、二段階の過程でテントに対しURIrefを与える。最初に全カタログに対し、URIrefを割り当てる、そして、カタログのテントの記述の中で相対URIrefを使用してこの特別な種類のテントを示す。
また、この相対URIrefの使用法は、相対URIrefをRDFから独立してテントに割り当てられた完全なURIreの省略形である、か、または、カタログ内のURIrefのテントへのに割り当てであると考えることができる。
カタログ外にあるRDFは、完全なURIrefを使用して、例えば、絶対URIrefhttp://www.example.com/2002/04/products#item10245を作り、テントの相対URIref #item10245をカタログの基本URIに結びつけることによって、このテントを参照できる。例えば、アウトドアスポーツのWebサイトexampleRatings.comは、RDFを使用して様々なテントの格付けを行うことができる。例
8で示しているテントへの(五つ星)格付けは、例
9のように、exampleRatings.comのWebサイト上で表示することができる。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:sportex="http://www.exampleRatings.com/terms/">
4. <rdf:Description rdf:about="http://www.example.com/2002/04/products#item10245">
5. <sportex:ratingBy>Richard Roe</sportex:ratingBy>
6. <sportex:numberStars>5</sportex:numberStars>
7. </rdf:Description>
8. </rdf:RDF>
例
9では、4行目では、rdf:Description要素と、テントの完全URIrefがその値であるrdf:about属性が使用されている。このURIrefを使用すると、格付けで参照されるテントは正確に認識できる。
これらの例では、いくつかのポイントを説明している。まず、RDFがURIrefのリソース(この場合、カタログのいろいろなテントとその他のアイテム)への割り当て方法を指定したり、制御したりしなくても、一つの文書(この場合、カタログ)をこれらのリソースの記述のソースとして識別する(RDF外の)プロセスとその文書内のリソースの記述における相対URIrefの使用法を組み合わせることによって、RDFでのURIrefのリソースへの割り当ての効果は期待できる。例えば、example.comはこのカタログを、製品のアイテム番号がカタログの中にない場合、その製品はexample.comで周知の製品ではない、という理解のもとに、製品について述べている中心となる情報源として使用することができる。
(RDFは、二つのリソース間に特定の関係が存在することを想定しない。なぜなら、これらのリソースのURIrefは全く同じ基礎を持っているか、似ているからである。この関係はexample.comでは周知だが、RDFでは直接定義はしていないということに注意。)
また、これらの例では、Webの構造上の基本原理を説明している。その原理とは、現行のリソース [BERNERS-LEE98]について、誰もが述べたいことを述べることができる、というものである。さらに、これらの例では、特定のリソースを記述するRDFはすべて一つの場所におく必要はなく、変わりに、Web上に配布されるということも示している。これは、ある組織が他の組織が定義したリソースに格付けをしたり、コメントしたりするような場合にだけ当てはまるものではなく、リソースの最初の定義者(または誰か)が、そのリソースについての詳細を提供することによって、リソースの記述を詳述したい場合などにも当てはまる。このことは、リソースが最初に記述されているRDF文書を変更して、詳細情報を記述するためにプロパティや値を追加したり、この例の様に、別の文書を作り、rdf:aboutを使用してURIref経由でオリジナルのリソースを参照するrdf:Description要素にプロパティや値を追加することによって行うことができる。
上記の協議では、#item10245などのフラグメント識別子は基本URIと関連して解釈される。デフォルトでは、この基本URIはフラグメント識別子が使用されているリソースのURIとなる。しかし、明示的にこの基本URIを指定できるようになることが望ましい場合もある。例えば、http://www.example.com/2002/04/productsにあるカタログに加え、example.orgがミラーサイト、例えば、http://mirror.example.com/2002/04/productsにカタログを複写したいと思う場合、カタログはミラーサイトからアクセスされる場合例に挙げているテントのURIrefは、http://www.example.com/2002/04/products#item10245ではなく、http://mirror.example.com/2002/04/products#item10245が作成され、収容する文書のURIから発生するため、障害が起こる。
そのため、明らかに意図したリソースとは違うものを参照することになる。
その代わり、example.orgは、その場所がベースを定義する一つのソース文書を発行することなく製品のURIrefのセットのために基本URIrefを割り当てたいと思うかもしれない。
そういった場合に対処するため、RDF/XMLは、XML文書が文書のURI以外の基本URIを指定することのできるXML ベース [XML-BASE]に対応している。
例
10では、XMLベースを使用したカタログの定義法を示している。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.com/terms/"
4. xml:base="http://www.example.com/2002/04/products">
5. <rdf:Description rdf:ID="item10245">
6. <exterms:model>Overnighter</exterms:model>
7. <exterms:sleeps>2</exterms:sleeps>
8. <exterms:weight>2.4</exterms:weight>
9. <exterms:packedSize>14x56</exterms:packedSize>
10. </rdf:Description>
...other product descriptions...
11. </rdf:RDF>
例
10では、4行目のxml:base宣言で、rdf:RDF要素(もう一つのxml:base属性が指定されるまで)内のコンテンツ用の基本URIは、http://www.example.com/2002/04/productsであり、そのコンテンツ内で引用されている相対URIrefは、たとえ収容している文書のURIが何であっても、すべてそのベースに相対的だと解釈される。その結果、テント#item10245の相対URIrefは、カタログ文書の実際のURIが何であっても、また、基本URIrefが多少なりとも特定の文書を識別しても、同じ絶対URIrefhttp://www.example.com/2002/04/products#item10245と解釈される。
これまで一製品の記述、example.comのカタログからのテントの特定の型、について述べてきた。しかし、example.comは、バックパックやハイキングブーツなどのような他の製品のカテゴリの複数のインスタンスと同様に、テントの異なる型も提供するだろう。物事を異なる種類や
カテゴリに分類するという考え方は、異なるタイプやクラスを持つ目的語 (object) のプログラミング言語の考え方と似ている。RDFは、あらかじめ定義されているプロパティrdf:typeを提供することによって、この考えに対応している。RDFリソースがrdf:typeプロパティで記述されると、そのプロパティの値は物事のカテゴリやクラスを表現するリソースだと考えられ、そのプロパティの主語 (subject)はそのカテゴリやクラスの
インスタンスであると考えられる。rdf:typeを使用して、例
11では、example.comが、製品の記述がテントの記述であることをどのように述べているかを示している。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.com/terms/"
4. xml:base="http://www.example.com/2002/04/products">
5. <rdf:Description rdf:ID="item10245">
6. <rdf:type rdf:resource="http://www.example.com/terms/Tent" />
7. <exterms:model>Overnighter</exterms:model>
8. <exterms:sleeps>2</exterms:sleeps>
9. <exterms:weight>2.4</exterms:weight>
10. <exterms:packedSize>14x56</exterms:packedSize>
11. </rdf:Description>
...other product descriptions...
12. </rdf:RDF>
例
11では、6行目のrdf:typeプロパティはインスタンスが、URIrefhttp://www.example.com/terms/Tentで識別されたクラスに属していることを示している。この場合、 example.comは(プロパティexterms:weightなどの)他の用語を表記するために使用するのと同じボキャブラリの一部として、そのクラスを記述し、そのため、それを参照するためにクラスの絶対URIrefを使用するということを考えてみる。
RDF自身、例であげているような、Tentなどの物事のアプリケーションン専用のクラスを定義するボキャブラリを定義しない。替わりに、そういったクラスはRDFスキーマで記述される。RDFで有しているアプリケーション専用のクラスやそのプロパティを記述するため機能については、第5節で述べている。DAML+OIL言語やOWL言語などのクラスを記述するための他の機能については、第5.5節で述べている。
特定のタイプやのインスタンスとしてリソースを記述していたり、クラスがかなり共通であるため、RDF/XMLはrdf:typeプロパティを使用してインスタンスの特別な省略形をクラスのメンバーとして提供している。この省略形では、rdf:typeプロパティとその値は削除され、rdf:Description要素が、クラスURIrefに相当するQNameという名前の要素で置き換えられる。また、この省略形を使用して、例
11example.comのテントは、以下の例
12の様に記述される。
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.com/terms/"
4. xml:base="http://www.example.com/2002/04/products">
5. <exterms:Tent rdf:ID="item10245">
6. <exterms:model>Overnighter</exterms:model>
7. <exterms:sleeps>2</exterms:sleeps>
8. <exterms:weight>2.4</exterms:weight>
9. <exterms:packedSize>14x56</exterms:packedSize>
10. </exterms:Tent>
...other product descriptions...
11. </rdf:RDF>
例
11と例
12はどちらも、XMLで直接書くことことのできる記述に非常に良く似た方法で、RDFステートメントをRDF/XMLに書き込むことができるということを示している。情報が構造化される方法で大きな変更を行わずにアプリケーションでRDFが使用できることを提案いるため、様々なアプリケーションでXMLの使用が増えているということを考えると、これは、重要な検討材料である。
上記の例では、RDF/XMLシンタックスの背景にある基本構想の一部について説明している。これらの例では、役に立つRDF/XMLを書き始めることができるよう十分な情報提供をしている。他に利用できるRDF/XMLの省略形と同様に、(ストライピングという)XMLでのRDFステートメントのモデリングの背景にある原理の詳細と、XMLでRDFを書き込むことについての詳細とその例に関しては、RDF/XML Syntax Specification [RDF-SYNTAX]を参照のこと。
4. その他RDFの機能
RDFには、リソースやRDFステートメントのグループを表現するための内蔵のタイプやプロパティ、ワールドワイドウェブにRDFを導入する機能などを含む、さらにたくさんの機能がある。
こういった機能については以下の節で述べる。
物事のグループを記述する必要が出てくる。例えば、複数の著者が本を作成したということを述べたり、あるコースの生徒や、パッケージのソフトウェアをリストしたりする場合があるかもしれない。RDFには、そういったグループを記述するために使用できるあらかじめ定義されたタイプやプロパティをいくつかある。
まず、RDには、あらかじめ定義されている三つのタイプ(と数個のあらかじめ定義されている関連のプロパティと一緒に)で構成されるコンテナ言語がある。コンテナとは、物事を含んでいるリソースのことである。含まれているものは、メンバーという。コンテナのメンバーはリソースまたは、リテラルであることができる。RDFは次の三つの種類のコンテナを定義している。
Bag (タイプrdf:Bagを持つリソース)
とは、メンバーの順序が重要ではない場合の複製のメンバーを含むリソースまたは、リテラルのグループのことである。例えば、Bagを使用してパート番号のエントリや処理の順番を重要視しないメンバーのグループを記述するために使用する。
Sequenceまたは、Seq
(タイプrdf:Seqを持つリソース)とは、メンバーの順序が重要である場合の複製メンバーを含むリソースやリテラルのグループのことである。例えば、Sequenceを使用してアルファベット順を維持しなければばらないグループを記述することができる。
Alternativeまたは、Alt (タイプrdf:Altを持つリソース)とは、
代替であるリソースまたは、リテラルのグループのことである(特に、プロパティの一つの値の場合)。例えば、Altを使用して本のタイトルの代替言語の翻訳を記述したり、リソースを検索できる代替のインターネットサイトのリストを記述したりできる。値がAltコンテナとなっているプロパティを使用したアプリケーションは、グループのメンバーのいずれか一つを適切なものとして選択できるということを認識する必要がある。
リソースをこのタイプのコンテナの一つとして記述するには、あらかじめ定義されたリソース、rdf:Bag、rdf:Seq、または、rdf:Alt(どれでもよい)のうちの一つを値とするrdf:typeプロパティを記述する。コンテナリソース(空白ノード、または、URIrefを持つリソース)は、グループを全体として表す。コンテナのメンバーは、コンテナリソースで各メンバーにコンテナメンバーシッププロパティを主語 (subject)として、そのメンバーを目的語 (object) として定義することによって、記述できる。このコンテナメンバーシッププロパティには、rdf:_nの形式の名前がある。nは、0より大きな整数で、0を伴わない。例えば、rdf:_1、rdf_2、rdf_3など。また、nは、特にコンテナのメンバーを記述するために使用される。コンテナメンバーシッププロパティとrdf:typeプロパティに加え、コンテナリソースにもコンテナを記述するプロパティが他にもある。
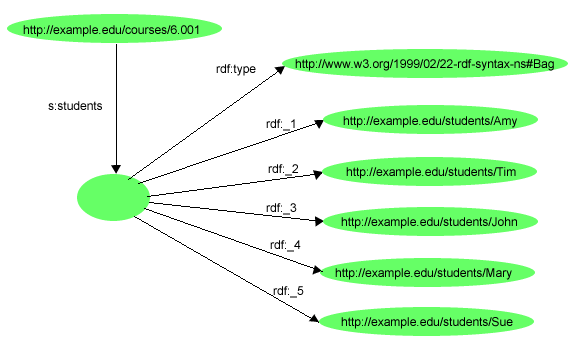
これらのタイプのコンテナがあらかじめ定義されたRDFタイプやプロパティを使用して記述される一方で、Altのメンバーが代替値などのようなコンテナと関連する特別な意味は、意図した意味であるということを理解することが重要である。これらの特別なコンテナタイプとその定義は物事のグループを記述する必要のある人達の間で共有の慣習を作ることを目的として提供される。RDFはすべて、コンテナの各タイプを記述するためのRDFグラフを作るために使用されるタイプやプロパティを提供する。RDFは、第3.2節で述べているタイプex:Tentのリースに関して理解している位にしか、タイプrdf:Bagのリースに関して理解はしていない。どの場合でも、各タイプに必要な特別な意味に従って動作するようにアプリケーションを書き込まなければならない。この点に関しては、以下の例で展開する。
コンテナの一般的な使用法として、プロパティの値が物事のグループであるということを示すということがある。例えば、「6.001コースにはAmy、Tim、John、Mary、そして、Sueがいる」という文章を表現するには、タイプrdf:Bag(生徒のグループ)のコンテナを値とするs:studentsプロパティを与えることによってコースを記述し、コンテナメンバーシッププロパティを使用し、個々の生徒をそのコンテナのメンバーであるとして、図
14のRDFグラフの様に記述することができる。
この例にあるs:studentsプロパティの値はBagと記述されているため、グラフのプロパティが名前に整数を含んでいても各生徒のURIrefに与えられている順番は重要ではない。それは、メンバーシッププロパティの名前の(明白な)順番を無視することは、rdf:Bagコンテナを含んでいるグラフを作成し、処理するアプリケーションによる。
RDF/XMLには、そういったコンテナをより簡単に記述することのできる特別なシンタックスや省略形がいくつかある。例えば、例
13では、 図
14のグラフについて示す。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.edu/students/vocab#">
<rdf:Description rdf:about="http://example.edu/courses/6.001">
<s:students>
<rdf:Bag>
<rdf:li rdf:resource="http://example.edu/students/Amy"/>
<rdf:li rdf:resource="http://example.edu/students/Tim"/>
<rdf:li rdf:resource="http://example.edu/students/John"/>
<rdf:li rdf:resource="http://example.edu/students/Mary"/>
<rdf:li rdf:resource="http://example.edu/students/Sue"/>
</rdf:Bag>
</s:students>
</rdf:Description>
</rdf:RDF>
例
13では、RDF/XMLはliを各メンバーシッププロパティを明示的に番号をつける必要性を回避するための便利な要素として与えることを示している。
番号をつけたプロパティrdf:_1、rdf:_2、などは、対応するグラフ作成時はli要素から発生する。要素名liは、HTMLからの用語「リスト項目」で ニーモニックとなるよう選択された。また、<s:students>プロパティ要素内での<rdf:Bag>要素の使用にも注意のこと。<rdf:Bag>要素は、
rdf:Description要素とrdf:type要素の両方を一つの要素で置き換えることのできる例
12で使用した省略形の別の例である。URIrefが指定されていないため、Bagは空白ノードである。<s:students>プロパティ要素内でBagをネストすることは、空白ノードがこのプロパティの値であることを示す省略法である。この省略の詳細については [RDF-SYNTAX]で述べている。
rdf:Seqコンテナのグラフの構造と、対応するRDF/XMLは、rdf:Bagのものと似ている (唯一の違いは、タイプrdf:Seqにある)。繰り返すが、rdf:Seqコンテナはシーケンスを記述するためのものであるが、適切に整数値のプロパティ名のシーケンスを解釈するのはグラフを作成し処理するアプリケーションによる。
Altコンテナの図の様に、「X11のソースコードは、ftp.example.org、
ftp.example1.org、または、ftp.example2.orgで参照できる」という文章は、図
15のRDFグラフで表すことができる
例
14では、図
15のグラフがどのようにRDF/XMLで書くことができるかを示す。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/packages/vocab#">
<rdf:Description rdf:about="http://example.org/packages/X11">
<s:DistributionSite>
<rdf:Alt>
<rdf:li rdf:resource="ftp://ftp.example.org"/>
<rdf:li rdf:resource="ftp://ftp.example1.org"/>
<rdf:li rdf:resource="ftp://ftp.example2.org"/>
</rdf:Alt>
</s:DistributionSite>
</rdf:Description>
</rdf:RDF>
Altコンテナは、プロパティrdf:_1で識別されているメンバーを少なくとも一つ持つにようにするためのものである。このメンバーは、デフォルト値、または、優先した値として考えられるようにするためのものである。rdf:_1として認識されているメンバー以外、残りの要素の順番は重要ではない。
書いている様に、図
15のRDFでは、単に、s:DistributionSiteのサイトプロパティの値はAltコンテナリソース自身であるとの述べている。別の意味としては、例えば、Altコンテナのメンバーのうちの一つはs:DistributionSiteサイトプロパティの値と考えられる、または、ftp://ftp.example.orgがデフォルトまたは優先された値であるというこのグラフが、特定のプロパティ(この場合、s:DistributionSite)に対して定義された意味にAltがどのような意図で挙動するかということの理解に組み込まれなければならない。そして、アプリケーションからも理解されなければならないということである。
Altコンテナは、言語タグとの連結で頻繁に使用される。例えば、タイトルが複数の言語に翻訳されている著作物には、各言語を持つAltコンテナを指し示すTitleプロパティがある。
BagとAltの意図した意味の違いについては、「ハックルベリーフィン」という本の原作者を考慮して詳細に説明できる。この本の著者は一人だが、二つの名前(マーク・トウェインとサミュエル・クレメンス)を持っている。どちらの名前も著者を指定するのに差し支えないものである。そのため、著者名のAltコンテナを使用すると(二つの別々の著者があることを意味する)Bagを使用するより正確にその関係を表すことができる。
ユーザは、ここで述べている方法を使用するよりも自由にリソースのグループを記述する方法を選択できる。RDFコンテナは、一般的に使用される場合、リソースのグループを含むデータをより相互運用可能にできる共通の定義として単に提供されているだけである。
これらのRDFコンテナタイプを使用するよりもはっきりとした代替がある場合がある。例えば、同じプロパティを使用して最初リソースを複数のステートメントの主語 (subject)にすることによって、特定のリソースと他のリソースのグループとの関係を示すことができる。これは、目的語 (object) が複数のメンバーを含んでいるコンテナである一つのステートメントの主語 (subject)であるリソースとは構造的には同じではない。これらの二つの構造は同じ意味を持つことが時々あるが、そうでない場合もある。任意の状態でどちらを使うかはこれを頭に置いて選択する必要がある。
作者と発行者との関係に関する例として考えると、以下の文章の様になる。:
Sueは、「Anthology of Time」と、「Zoological Reasoning」、「Gravitational
Reflections」を書いた。
この場合、同じ作者が別々に書いた三つのリソースがある。これは、以下の様に繰り返したプロパティを使用して表現できる。
exstaff:Sue exterms:publication ex:AnthologyOfTime .
exstaff:Sue exterms:publication ex:ZoologicalReasoning .
exstaff:Sue exterms:publication ex:GravitationalReflections .
この例では、同じ人が書いたという事以外、発行物の関係を述べてはいない。ステートメントはそれぞれ、独立した事実なので、プロパティを繰り返し使用することは当然の選択である。しかし、このことは、Sueが書いたリソースについてのステートメントとして以下の様に合理的に表現される。
exstaff:Sue exterms:publication _:z
_:z rdf:type rdf:Bag .
_:z rdf:_1 ex:AnthologyOfTime .
_:z rdf:_2 ex:ZoologicalReasoning .
_:z rdf:_3 ex:GravitationalReflections .
逆に、以下の文章
Fred、Wilma、Dinoが所属している議事運営委員会で、決議案が承認された。
では、委員会は全体でその決議を承認したことを述べているが、各委員会のメンバーのそれぞれがその決議に賛成したということを必ずしも述べているわけではない。この場合、この文章を次のように三つのexterms:approvedByステートメント、(その内一つが書く委員会のメンバー)として作成することは、恐らく誤解を招く可能性がある。
ex:resolution exterms:approvedBy ex:Fred .
ex:resolution exterms:approvedBy ex:Wilma .
ex:resolution exterms:approvedBy ex:Dino .
なぜなら、上記のステートメントでは、各メンバーが個々に決議を承認しているからである。
この場合、主語 (subject)が決議、目的語 (object) が委員会自身である 、一つのexterms:approvedBy ステートメントとして、以下のトリプルの様に文章を作成する方が良いだろう。委員会のリソースは、委員会のメンバーがそのメンバーとなっているBagとして以下の様にトリプルで記述することができる。
ex:resolution exterms:approvedBy ex:rulesCommittee
ex:rulesCommittee rdf:type rdf:Bag .
ex:rulesCommittee rdf:_1 ex:Fred .
ex:rulesCommittee rdf:_2 ex:Wilma .
ex:rulesCommittee rdf:_3 ex:Dino .
最後に、プログラミング言語データ構造を構築しているので、これらのRDFコンテナを使用する際は、コンテナを構築しているのではなく、実際に存在するコンテナ(物事のグループ)を記述しているということを理解することが大切である。例えば、上記の議事運営委員会例では、RDFでそのように記述しているかしていないかに関係なく議事運営委員会は、不規則なグループである。値がrdf:Bagである議事運営委員会のリソースrdf:typeプロパティを入力場合は、グループのメンバーを含むための特定のデータ構造を構築しているのではなく、単に議事運営委員会をタイプrdf:Bagのものと関連させる文字を何でも持っているとして記述しているだけである(議事運営委員会は、メンバーをまったく記述していないBagであると示すことができる)。同じように、コンテナ・メンバーシップ・プロパティを使用する場合は、単位コンテナリソースがあるものをメンバーとして持っていると記述しているだけである。メンバーとして記述するものは存在するメンバーだけである、と必ずしも述べる必要は無い。例えば、上記のトリプルを入力して、議事運営委員会ではFred、Wilma、DinoがBagのメンバーであるが、Bagの唯一のメンバーではないと記述する。
第4.1節
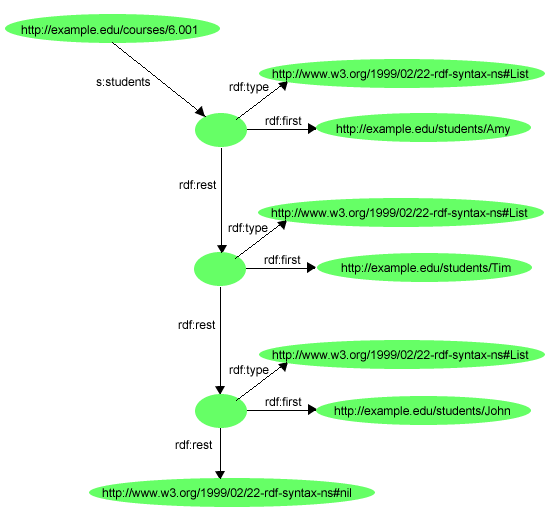
で述べたコンテナの制限とは、コンテナをクローズする
方法がないということである。例えば、「これらはコンテナのメンバーすべてである」と述べることなど。なぜなら、一つのグラフでは、メンバーの一部を述べることができるが、その他のメンバーを記述する別のグラフの存在の可能性を排除する方法がないからである。RDFは、指定したメンバーだけを含むグループをRDFコレクションの形で記述することに対応する。RDFコレクションとは、RDFグラフのリスト構造として表現されている物事のグループのことである。このリスト構造はあらかじめ定義されているコレクション・ボキャブラリを使用して構築される。このコレクション・ボキャブラリは、あらかじめ定義されているタイプrdf:List、あらかじめ定義されているプロパティrdf:firstと、rdf:rest、あらかじめ定義されているリソースrdf:nilで構成されている。
このことを説明するために、図16のグラフを使用して「コース6.001の生徒は、Amy、Tim、Johnである」という文章を表現することができる。
s:Amyなどのコレクションのそれぞれのメンバーに関しては、対応するタイプrdf:Listが存在する。このリストリソースは、rdf:first プロパティでコレクションメンバーと、rdf:rest
プロパティでリストの残りとそれぞれリンクしている。リストの終わりは、リソースrdf:nilであるrdf:restプロパティで示している。この構造はLispプログラミング言語を知っている人にはお馴染みのものである。Lispでは、rdf:firstプロパティとrdf:restプロパティでアプリケーションはこの構造をトラバースできる。
RDF/XMLは、コレクションの記述を簡単にする表記を実現する。
RDF/XMLでは、コレクションは、属性rdf:parseType="Collection"を持ち、コレクションのメンバーを表現しているネストされた要素のグループを含む。rdf:parseType="Collection"属性は、囲まれた要素を使用して対応するリスト構造をRDFグラフに作成するということを示している。
これがどう作用するのかを説明するため、図 16のRDF/XMLが例 15のRDFグラフになることを示す。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.edu/students/vocab#">
<rdf:Description rdf:about="http://example.edu/courses/6.001">
<s:students rdf:parseType="Collection">
<rdf:Description rdf:about="http://example.edu/students/Amy"/>
<rdf:Description rdf:about="http://example.edu/students/Tim"/>
<rdf:Description rdf:about="http://example.edu/students/John"/>
</s:students>
</rdf:Description>
</rdf:RDF>
rdf:parseType="Collection" を使用すると、図
16で示しているようなリスト構造の構成を示すことになる。これは、固定された項目の制限されたリストを任意の長さで定義し、rdf:nilで終了し、リスト構造自身に一意である”新しい”空白ノードを使用する。
しかし、RDFはRDFコレクションボキャブラリを使用する特別な方法を強制 しないので、他の方法でこのボキャブラリを使用することができる。
その方法の中にはリストを記述しなくてもよいものもある。例えば、任意のノードにはrdf:firstプロパティの異なる二つの値があることを断言したり、単にコレクションの記述の一部を省略しても違法ではない。
そのため、一般的には、よく構成される構造を必要とするRDFアプリケーションは、完全に強力なものにするため収集ボキャブラリが適切に使用されていることを確認するために作成される必要がある。
RDFアプリケーションは、ステートメントに関するステートメントを作成する必要がある場合がある。例えば、ステートメントがいつ作成されたのか、誰が作成したのか、または、そういった情報などを記録する場合など。
例として、第3.2節で述べたテントについてのステートメントを考える。
product item10245 has a weight whose value is
2.4
トリプル表現では、以下のようになる。
exproducts:item10245 exterms:weight "2.4" .
このステートメントはJohn SmithがRDFで作成した、と述べるとする。RDFでは、リソースについてのステートメントを作成できるので、以下の様にできる。
[[exproducts:item10245 exterms:weight "2.4" .]] dc:creator exstaff:85740 .
つまり、オリジナルのステートメントをリソースに変えることができるので、オリジナルのステートメントをリソースについて述べている別のRDFステートメントの主語 (subject)にすることができる。
RDFは、ステートメントをリソースとしてモデリングする内蔵するボキャブラリを持っている。このモデリングをRDFでの具体化 と言い、ステートメントのモデルをステートメントの具体化と言う。
RDF具体化ボキャブラリは、rdf:Statementタイプと
rdf:subjectプロパティ、rdf:predicateプロパティ、
rdf:objectプロパティで構成されている。このボキャブラリでは、トリプルは以下の形式になる。
foo rdf:type rdf:Statement .
これは、リソースfooは一部のRDFではRDFトリプルであるステートメントであるということである。rdf:subject、rdf:predicate、rdf:objectの三つのプロパティはfooに適用されると、トリプルfoo主語 (subject)コンポーネント、述語 (predicate)コンポーネント、目的語 (object) コンポ-ネントを指定する。
このボキャブラリを使用して、オリジナルのトリプルの具体化は以下の様になる。
exproducts:item10245 exterms:weight "2.4" .
グラフにで記述すると、
_:xxx rdf:type rdf:Statement .
_:xxx rdf:subject exproducts:item10245 .
_:xxx rdf:predicate exterms:weight .
_:xxx rdf:object "2.4" .
(最初のトリプルを参照するために表すノード、つまり、具体化の空白ノード
_:xxx は空白ノードでもURIrefのどちらでもよい。)
このような意図された具体化の解釈は、
_:xxx が具体化の主語 (subject)、述語 (predicate)、目的語 (object) で記述されるオリジナルのトリプル(全体的な)への参照として理解される必要があるということである。そのため、具体化を使用すると、以下の様にオリジナルのステートメントがグラフを使用してJohnSmithによって作成されたという事実を表現できる。
_:xxx rdf:type rdf:Statement .
_:xxx rdf:subject exproducts:item10245 .
_:xxx rdf:predicate exterms:weight .
_:xxx rdf:object "2.4" .
_:xxx dc:creator exstaff:85740 .
意図された解釈は、_:xxx が参照するトリプルが同じ主語 (subject)や述語 (predicate)、目的語 (object) を持つ任意のトリプルである、ということではなく、特定のRDF文書のトリプルの特定なインスタンス であるということであるとうことに注意。 同じ主語 (subject)、述語 (predicate)、目的語 (object) を持つトリプルがあるかもしれない。グラフがトリプルのセットだと定義されているが、同じトリプル構造を持つインスタンスの中には、異なる文書で発生するものがある。そのため、これを理解していないと、_:xxxが最初のグラフのトリプルを参照しないが、同じ構造を持つ他のトリプルのいくつかを参照するということが重要になるかもしれない。具体化は(例にあるような)編成日やソース情報などのプロパティを表現するのに使用することを目的としていて、これらのプロパティはトリプルの特定のインスタンスに適用される必要があるため、この特別な具体化の解釈が使用される。
また、具体化されたステートメントを主張することはオリジナルのステートメントを主張することでもないし、その他を意味することでもないということにも注意。それは、Johnがfooについての述べたということを誰かが主張する場合、Johnが述べたのはfoo自身であるということを主張していない。逆に、誰かがfooを主張した場合、その具体化を主張しているのではない。なぜなら、fooを主張することによって述べるつもりのステートメントとしてそういったことが存在すると述べているわけではないからである。
上記では、具体化の表現された解釈についての述べた。その理由は、この解釈は、具体化が使用される際に一般的に使用される解釈であるが、RDF具体化は実際にはこの意味すべてを捉えているわけではないからである。特にRDFシンタックスはそれ自身に、RDFトリプルとその具体化を”結びつける”方法がないからである。以下はそのグラフである。
_:xxx rdf:type rdf:Statement .
_:xxx rdf:subject exproducts:item10245 .
_:xxx rdf:predicate exterms:weight .
_:xxx rdf:object "2.4" .
_:xxx dc:creator exstaff:85740 .
ここでは、実際に「主語 (subject)exproducts:item10245と述語 (predicate)exterms:weight目的語 (object) 2.4があり、Johnが作成したステートメントがある」ということを述べている。(_:xxxが参照している) ステートメントは、特定のRDF文書の特定のいくつかのステートメントと同じであるといういことを述べてはいない。
これを理解するには、オリジナルのトリプルを以下の様に入力する。
exproducts:item10245 exterms:weight "2.4" .
そして、その具体化は、具体化をもつJohnと関連する更なるトリプルと一緒に以下のようになる。
_:xxx rdf:type rdf:Statement .
_:xxx rdf:subject exproducts:item10245 .
_:xxx rdf:predicate exterms:weight .
_:xxx rdf:object "2.4" .
_:xxx dc:creator exstaff:85740 .
_:xxxとオリジナルのトリプルが明示的に関連するものはまったく無いので、これをJohnが作成したと述べることができる。
これは、こういった”由来”の情報がRDFでは表現できないというわけではなく、具体化ボキャブラリと関連する意味のRDFを使用するだけでは表現できないと言う意味である。例えば、RDF文書(例、Webページ)にはURIがあり、そのURIで識別されるリソースについてのステートメントを作成し、こういったステートメントがどの様に解釈されるべきかということについてのアプリケーション依存の理解を元に、まるでステートメントがその文書の中で(平等に適用する)ステートメントすべてをめぐって”紛争”するかの様に作用することができる。また、URIを個々のRDFステートメントに割り当てるための(RDF外に)メカニズムがいくつか存在する場合、認識を行うためのURIを使用してそのステートメントに関するステートメントを確かに作成することができる。
そういった場合、具体化ボキャブラリを使用する必要は全くない。
これを理解するには、オリジナルのトリプルがURIを持つ場合、例えば、ex:statementfoo、Johnへのステートメントはステートメントによるものだと考えることができる。
ex:statementfoo dc:creator exstaff:85740 .
上記では、具体化ボキャブラリを使用していない。
更に、上記の意図された解釈に従って直接的に具体化ボキャブラリを使用することもできるし、特定のトリプルをその具体化に関連付ける方法に関してのアプリケーション依存の理解をすることもできる。しかし、このRDFを受ける他のアプリケーションは、必ずしもこのアプリケーション依存の理解を共有する必要はないので、適切にグラフを解釈する必要もない。
最後に、RDFグラフやグラフのトリプルとトリプルの具体化との間の関係が一対一である必要はないので、具体化で記述されているいくつかのリソースに関するプロパティは、同じコンポーネントを持っていても同じプロパティが他のリソースを適用しているということを述べる必要はない。例えば、以下のグラフについて考えると、
_:xxx rdf:type rdf:Statement .
_:xxx rdf:subject exproducts:item10245 .
_:xxx rdf:predicate exterms:weight .
_:xxx rdf:object "2.4" .
_:yyy rdf:type rdf:Statement .
_:yyy rdf:subject exproducts:item10245 .
_:yyy rdf:predicate exterms:weight .
_:yyy rdf:object "2.4" .
_:xxx dc:creator exstaff:85740 .
以下の様にはならない。:
_:yyy dc:creator exstaff:85740 .
第2.3節では、RDFモデルが元来2項関係のみをサポートしているということを述べた。つまり、ステートメントは二つのリソース間の関係を指定すると言うことである。例えば、以下のステートメント
exstaff:85740 exterms:manager exstaff:62345 .
は、「manager」には二人の雇用者がいる(恐らく、一人がもう一人を管理している)ということを述べている。
しかし、RDFでより高い項目の関係(三つ以上のリソース間の関係)を含む情報を表現する必要がある場合がある。これについては第2.3節で述べている。ここでは、Smithとそのアドレス情報の関係を表現することが問題であり、Johnのアドレスの値はその住所のストリート、市、州、郵便番号の構造化された値である。これを関係として書く場合、アドレスは以下の形の5項関係であるということがわかる。
address(exstaff:85740, "1501 Grant Avenue", "Bedford",
"Massachusetts", "01730")
述べる物事の集合(ここでは、Johnのアドレスを表現するコンポーネントのグループ)を別々のリソースとして考え、以下の様にトリプルで新しいリソースについて別々のステートメントを作成することで、こういった構造化された情報をRDFで表現できるということを述べた。
exstaff:85740 exterms:address _:johnaddress .
_:johnaddress exterms:street "1501 Grant Avenue" .
_:johnaddress exterms:city "Bedford" .
_:johnaddress exterms:state "Massachusetts" .
_:johnaddress exterms:Zip "01730" .
(ここでは、_:johnaddressは Johnのアドレスを表現している空白ノードの空白ノード識別子である。)
これは、n項関係をRDFで表現する一般的な方法である。つまり、参加しているもの(ここではJohn)の一つを選び、オリジナルの関係(ここではaddress)の主語 (subject)として扱う。そして、中間のリソースを選択して残りの関係(URIを割り当てても割り当てなくても)を表現し、その関係の残りのコンポーネントを示す新しいプロパティを与える。
Johnのアドレスの場合、構造化された値の個々の部分をexterms:addressプロパティ「主な」値とは考えられない。すべて等しくその値の原因となる。しかし、他の文脈上の情報を提供する関係や主な値を修飾するその他の情報がある場合の構造化された値の部分の一つが「主な」値として考えられることもある。例えば、第3.2節のテントの例では、プレーンなリテラル「2.4」などとして記述している特定のテントの重さを取り扱っている。
exproduct:item10245 exterms:weight "2.4" .
事実、重さに関するより複雑な記述としては、単に「2.4」ではなく、「2.4キログラム」というのがある。これを述べるには、
exterms:weightプロパティにリテラル「2.4」と測定単位の記述(キログラム)の二つのコンポーネントが存在する必要がある。この場合、リテラル「2.4」は、プロパティの「主な」値と考えることができる。なぜなら、述べていない情報を埋めるためにこの値は文脈の理解に依存し、(上記のトリプルの様に)単に値「2.4」として頻繁に記録されるからである。
RDFモデルでは、この種の修飾されたプロパティ値は、ただ単に他の種類の構造化された値だと考えられる。それを示すには、別のリソースを使用して全体(この場合重さ)として構造化された値を表現し、オリジナルのステートメントを目的語 (object) として取り扱う。その後、構造化された値の個々の部分を表現するリソースプロパティを入力する。この場合、リテラル”2.4”のプロパティと、単位”キログラム”の値が必要である。RDFはあらかじめ定義されているrdf:valueプロパティを提供し構造化された値の主要となる値(もし一つあれば)を記述する。そのため、リテラル”2.4”をrdf:valueプロパティの値として、リソースexunits:kilogramsを
exterms:unitsプロパティとして入力する(リソース
exunits:kilogramsは、example.org スキーマにURIref
http://www.example.org/units/kilogramsで定義されている)。結果として以下のトリプルとなる。
exproduct:item10245 exterms:weight _:weight10245 .
_:weight10245 rdf:value "2.4" .
_:weight10245 exterms:units exunits:kilograms .
RDF/XMLを使用すると 例
16の様に置き換えることができる。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.com/2002/04/products#item10245">
<exterms:weight rdf:parseType="Resource">
<rdf:value>2.4</rdf:value>
<exterms:units rdf:resource="http://www.example.org/units/kilograms" />
</exterms:weight>
</rdf:Description>
</rdf:RDF>
(例 16 では、第3節
で紹介していないが、[RDF-SYNTAX]で述べている他のRDF/XMLの省略形を使用している。)
分量を表現するために、異なる分類スキーマやレイティングシステムからの値や主な値をプロパティにに与えるためにrdf:valueプロパティを使用したり、または、別のプロパティを使用して分類スキーマや値を詳しく述べるためにほかの情報を識別したりするのと同様に、測定単位を使用して、同じ方法が使用できる
その目的で、rdf:valueを使用する必要はない(例えば、上記の例のex:amountなど自身のプロパティ名を割り当てることができる)、RDFは、特定の意味とそれを関連付けない。
こういった良くある状況では、rdf:valueは単に便宜上で提供されたものである。
5.RDFボキャブラリの定義: RDF
スキーマ
RDFは、名づけられたプロパティと値を使用して、リソースに関しての簡単なステートメントを表現する方法を提供する。しかし、RDFユーザコミュニティにも、特定の種類やリソースのクラスを記述していると示す機能が必要で、そういったリソースを記述する際は特定のプロパティを使用する。例えば、第3.2の例の会社 example.comが、exterms:Tentなどのクラスを記述したいとする場合、exterms:model、exterms:weightInKg、exterms:packedSize、などのプロパティを使用してそれを記述する(クラスやプロパティの名前として様々な「例」のネーム空間プリフィックス(接頭辞)でQNamesを使用している。ここでは、第2.1節で述べたように、RDFではこれらの名前が実際にURI参照であるということの注意として使用する)。同じように、人名リソースの記述に関心のある人たちは、ex2:Bookや、ex2:MagazineArticleなどのクラスを記述しex2:author、ex2:title、または、ex2:subjectなどのプロパティを使用して記述する。他のアプリケーションでは、 ex3:Personやex3:Companyなどのようなクラス、ex3:ageやex3:jobTitle、 ex3:stockSymbol、ex3:numberOfEmployeesなどのようなプロパティを使用するかも知れない。RDF自身、これらを指定するためのボキャブラリを持たない。その代わり、そういったクラスやプロパティは、RDFボキャブラリで記述される。RDF ボキャブラリを記述する機能は、RDF Vocabulary
Description Language 1.0: RDF Schema [RDF-VOCABULARY]で指定されている。
RDFスキーマは、exterms:Tent、ex2:Book、ex3:Personなどのクラスや、exterms:weightInKg、ex2:author、ex3:JobTitleなどのプロパティのようなアプリケーション志向の特定なボキャブラリを提供しない。そのかわり、そういったクラスとプロパティをボキャブラリの一部として
指定し、一緒に使用されると考えられるクラスやプロパティを示すために必要なメカニズムを提供する(例えば、ex3:Personを記述する際にex3:jobTitleプロパティが使用されると考える)。つまり、RDFスキーマは、RDFへ
タイプシステムを提供する。 RDFスキーマのタイプシステムは、Javaなどオブジェクト指向プログラミング言語のタイプシステムにどこか似ている。例えば、RDFスキーマを使用すると、リソースを一つ以上のクラスのインスタンスとして定義できる。さらに、 クラスを階層形式に整列させることもできる。例えば、クラスex:Dogは、ex:Animalのサブクラスであるex:Mammalのサブクラスとして定義できる。つまり、クラスex:Dogにあるリソースはいずれも、ex:Animalクラスの中にあると考えられる、という意味である。しかし、RDFクラスとプロパティは、プログラミング言語タイプとはかなり異なる部分があるということである。RDFクラスとプロパティの記述は、 情報が強制されなければならない拘束を作成しないが、記述するRDFリソースについての詳細情報を提供する。この情報は様々な方法で使用できる。この点についての詳細は、第5.3節で述べることにする。
RDFスキーマは、あらかじめ定義されたRDFリソースとプロパティのセットをユーザ専用のクラスとプロパティを記述するのに使用することのできるそれらの意味と一緒に提供することによって、RDF自身を使用してRDFタイプシステムを指定する。RDFに拡張したこの付加的なRDFスキーマリソースには、詳細な意味を持つより多くの予約ボキャブラリが含まれている。RDFスキーマ(RDFS)ボキャブラリは、URI参照 http://www.w3.org/2000/01/rdf-schema#"で特定されるネーム空間で定義されている(ここで示す例では、プリフィックス(接頭辞)rdfs: を使用してこのネーム空間を引用する)。RDFスキーマの基本リソースとプロパティに関しては、次の節で述べることにする。
いずれの種類の記述プロセスの基本手順は、記述する様々な物事を特定することである。RDFスキーマは、これらの「物事の種類」をクラスとして参照する。RDFスキーマのクラスは、Javaなどのオブジェクト指向のプログラミング言語のクラスの概念と少し似ているタイプやカテゴリの概念に相当する。RDFクラスは、Webページ、人、文書の種類、データベース、や抽象的な概念など物事のほとんどのカテゴリを表現するために使用できる。クラスは、RDFSで定義されているリソースrdfs:Classや rdfs:Resource、プロパティrdf:typeやrdfs:subClassOfを使用して記述される。
例えば、RDFを使用して異なる種類の自動車についての情報を提供したい場合を考える。RDFスキーマでは、ます、自動車であるという物事のカテゴリを表現するためにクラスが必要である。クラスに所属するリソースのことをインスタンスという。この場合、クラスのインスタンスを自動車であるリソースにするとする。
RDFスキーマでは、クラス は、値がRDFSで定義されたリソースrdfs:Classであるrdf:type プロパティを持つ任意のリソースである。そのため、自動車のクラスは、クラスにURIrefを割り当てることによって記述される。例えば、ex:MotorVehicle (ex:を使用してネーム空間URIref
http://www.example.org/schemas/vehiclesを表す。これはここの例で使用する)
と、値がRDFSで定義されているリソースrdfs:Classであるrdf:typeプロパティでそのリソースを記述する場合。つまりRDFステートメントを以下の様に書く場合。
ex:MotorVehicle rdf:type rdfs:Class .
第3.2節で述べたように、プロパティrdf:typeは、リソースがクラスのインスタンスであると示すために使用される。そのため、ex:MotorVehicleをクラスとして記述して、リソースex:companyCar が自動車であると記述したい場合は、以下の様なRDFステートメントを記述する
ex:companyCar rdf:type ex:MotorVehicle .
(プロパティ名とインスタンス名の最初の文字は小文字で書かれているが、私たちは、クラス名の最初の文字を大文字で書くという頻繁に使用される従来の習慣を採用している。しかし、この習慣はRDFSでは必要ない。)
リソースrdfs:Class自身には、rdfs:Classのrdf:typeがある。リソースは、複数のクラスのインスタンスであってもよい。
クラスex:MotorVehicleを記述したら、自動車専用の様々な種類を示すクラスをさらに記述したいと考えるかもしれない。例えば、乗用車、バン、ミニバン、など。これらのクラスは、新しいクラスに対しURIrefを割り当て、例えば以下の様に、これらのリソースを記述するRDFステートメントを書き込むことによって、クラスex:MotorVehicleを記述したのと同じ方法で記述することができる。
ex:Van rdf:type rdfs:Class .
ex:Truck rdf:type rdfs:Class .
しかし、個々のクラスの記述ではなくそれ以上のことを行いたい。つまり、MotorVehicleの専用の種類であるクラスex:MotorVehicleへの関係を示したい場合。その場合、サブクラスのRDFS概念を使用する。
RDFサブクラスは、二つのクラスのサブセット/スーパーセット関係を表す。この関係をあらかじめ定義されたrdfs:subClassOfプロパティを使用して二つのクラスを関連付けて記述する。例えば、ex:Vanは、ex:MotorVehicleのサブクラスであることを述べるには、以下のRDFステートメントを作成する。
ex:Van rdfs:subClassOf ex:MotorVehicle .
rdfs:subClassOf関係の意味は、リソース ex:companyVanが、ex:Vanのインスタンスである場合、ex:companyVanも黙示的にex:Motorvehicleのインスタンスであると考えられる(つまり、明示的に述べられていなくてもex:companyVanはex:MotorVehicleのインスタンスであると「推測」したり、またそのような振舞うことができる)。
rdfs:subClassOfプロパティは、推移的である。この意味は、例えば、以下のRDFステートメントを書く場合、
ex:Van rdfs:subClassOf ex:MotorVehicle .ex:MiniVan rdfs:subClassOf ex:Van .
ex:MiniVanも黙示的にex:Motorvehicleのサブクラスとなる。 その結果、(クラスex:Vanと同様に)クラスex:MiniVanのインスタンスであるリソースは、クラスex:Motorvehicleのインスタンスとも考えられる。クラスは、複数のクラスのサブクラスになってもよい(例えば、ex:MiniVanは、ex:Vanとex:PassengerVehicleの両方のサブクラスになることができる)。(すべてのクラスに所属するインスタンスはリソースなので)クラスはすべて、黙示的にクラスrdfs:Resourceのサブクラスである。
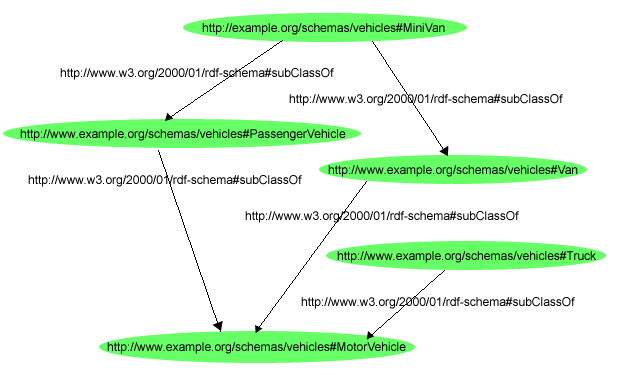
図 17では、今話題としているフルクラスの階層を示している。
このスキーマは、トリプルで以下の様に記述できる。
ex:MotorVehicle rdf:type rdfs:Class .
ex:PassengerVehicle rdf:type rdfs:Class .
ex:Van rdf:type rdfs:Class .
ex:Truck rdf:type rdfs:Class .
ex:MiniVan rdf:type rdfs:Class .
ex:PassengerVehicle rdfs:subClassOf ex:MotorVehicle .
ex:Van rdfs:subClassOf ex:MotorVehicle .
ex:Truck rdfs:subClassOf ex:MotorVehicle .
ex:MiniVan rdfs:subClassOf ex:Van .
ex:MiniVan rdfs:subClassOf ex:PassengerVehicle .
例 17では、このスキーマがRDF/XMLでどのように記述されるかを示している。
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<rdf:Description rdf:ID="MotorVehicle">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="PassengerVehicle">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="Truck">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="Van">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="MiniVan">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#Van"/>
<rdfs:subClassOf rdf:resource="#PassengerVehicle"/>
</rdf:Description>
</rdf:RDF>
このRDF/XMLでは、第3.2節で述べている様なスキーマ文書に関連するURIrefを「割り当てる」ことの効果を出すためにrdf:IDを使用して記述しているリソース(クラス)に対し、MotorVehicleなどの名前を導入している。そして、これらの名前を元にしている相対URIrefは、同じスキーマと一緒に他のクラス定義で使用できる(例えば、他のクラスの記述で#MotorVehicleを使用したように)。スキーマ自身がリソースhttp://example.org/schemas/vehiclesであると仮定して、このクラスのフルURIrefは、 (図
17で示したように)
http://example.org/schemas/vehicles#MotorVehicleとなる。第3.2節で述べたように、スキーマが移動したりコピーされたりした場合でもこれらのスキーマクラスへの参照が一貫して維持されるようにするには(または、スキーマクラスがすべて一つの場所で発行されたと仮定せずに、ただ単にスキーマクラスへ基本URIrefを割り当てる場合)、クラス記述にも明示的なxml:base="http://example.org/schemas/vehicles"
宣言を含めることができる。.
どこにでも存在するRDFインスタンスデータ(例えば、これらのクラスの個々の自動車を記述するデータなど)でこれらのクラスを参照するには、そのクラスを識別するためのフルURIrefを使用する必要がでてくる。例えば、リソースex2:companyCarをこのスキーマに記述されているクラスex:MotorVehicleのインスタンスとして記述するには、例
18の様にRDF/XMLを使用することができる。
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/schemas/vehicles">
<rdf:Description rdf:ID="companyCar">
<rdf:type rdf:resource="http://example.org/schemas/vehicles#MotorVehicle"/>
</rdf:Description>
</rdf:RDF>
記述する物事の特定のクラスの記述に加え、ユーザコミュニティは(乗用車を記述するためのrearSeatLegRoomなどの)物事のクラスを特徴づける特定のプロパティ記述できなければならない。RDFスキーマでは、プロパティはRDFで定義されているクラスrdf:PropertyとRDFSで定義されているプロパティ rdfs:domain、rdfs:range、rdfs:subPropertyOfを使用して記述される。
RDFのプロパティはすべて、クラスrdf:Propertyのインスタンスとして記述される。そのため、 exterms:weightInKgなどの新しいプロパティは、プロパティにURIrefを割り当て、値がリソースrdf:Propertyであるrdf:typeプロパティでそのリソースを記述することによって、記述される。つまり、以下のRDFステートメントを作成する。
exterms:weightInKg rdf:type rdf:Property .
また、RDFスキーマは、プロパティとクラスがRDFデータで一緒にどのような意図で使用されるのかを記述するボキャブラリを提供する。この種の最も重要な情報は、RDFSで定義されているプロパティrdfs:range とrdfs:domainを使用してアプリケーション専用のプロパティを詳細に記述することによって提供される。
rdfs:rangeプロパティは、特定のプロパティが指定したクラスのインスタンスであるということを述べるために使用される。例えば、プロパティex:authorにクラスex:Personのインスタンスである値があることを示したい場合、以下のRDFステートメントを作成する。
ex:Person rdf:type rdfs:Class .
ex:author rdf:type rdf:Property .
ex:author rdfs:range ex:Person .
これらのステートメントでは、ex:Personがクラスで、ex:author がプロパティであり、ex:authorを使用しているRDFステートメントには、目的語 (object) として、 ex:Personのインスタンスが含まれているということを示している。
例えば、プロパティex:hasMotherが0、1、または複数の範囲のプロパティを持つことができる場合。ex:hasMotherが範囲プロパティを持たない場合、 ex:hasMotherプロパティの値について何も述べることはない。 ex:hasMotherに、例えば、範囲としてex:Personを指定するものなどの一つの範囲プロパティがある場合、ex:hasMotherプロパティの値はクラスex:Personのインスタンスである、ということである。また、例えば、その範囲としてex:Personを指定するものと、ex:Femaleを指定するものなど、 ex:hasMotherプロパティが複数の範囲プロパティを持つ場合、ex:hasMotherプロパティの値は 、範囲として指定した すべてクラスのインスタンスであるリソースとなるということである。例えば、ex:hasMotherのいずれの値もex:Female と ex:Personの両方の値となるということである。
また、第2.4節で述べた様に、rdfs:rangeプロパティはプロパティの値は型付き(typed)リテラルによって与えられたことをを示すために使用できる。例えば、プロパティex:ageにはXMLデータタイプxsd:integerからの値があるということを述べる場合、以下のRDFステートメントを作成する。
ex:age rdf:type rdf:Property .
ex:age rdfs:range xsd:integer .
データタイプxsd:integerは、自身のURIrefで認識される (フルURIrefは、 http://www.w3.org/2001/XMLSchema#integerとなる)。このURIrefは、RDFデータスキーマでデータタイプを識別するということを明示的に述べなくても使用できる。しかし、任意のURIrefがデータタイプを識別するということを明示的に述べることが便利な場合もある。 これは、RDFSで定義されたクラスrdfs:Datatypeを使用することで可能となる。xsd:integerがデータタイプであると述べるには、以下のRDFステートメントを作成する。
xsd:integer rdf:type rdfs:Datatype .
このステートメントでは、xsd:integerは([RDF-CONCEPTS]で述べているRDFデータタイプの要件に一致すると思われる)データタイプのURIrefであることを述べている。 そういったステートメントは、データタイプの定義を設定しない。例えば、新規のデータタイプを定義するという観点においてなどで。 RDFSでデータタイプを定義する方法はない。第2.4節で述べたように、データタイプは外見的にはRDFSに定義され、URIrefでRDFステートメントで参照される。このステートメントが行うことは、データタイプの存在を記録し、明示的にそのタイプがこのスキーマで使用されることを述べることである。
rdfs:domainプロパティは、特定のプロパティが指定したクラスに適用することを述べるために使用される。例えば、プロパティex:authorがクラスex:Bookのインスタンスに適用すると述べる場合、以下のRDFステートメントを作成する。
ex:Book rdf:type rdfs:Class .
ex:author rdf:type rdf:Property .
ex:author rdfs:domain ex:Book .
これらのステートメントは、ex:Personがクラスで、ex:authorがプロパティであり、ex:authorプロパティを使用するRDFステートメントには、主語 (subject)としてex:Bookのインスタンスがあるということを示している。
例えば、任意のプロパティexterms:weightが0、1、または複数のドメインプロパティを持つことができる場合。exterms:weightにドメインプロパティがない場合は、exterms:weightプロパティが一緒に使用されるリソースについて何も述べることがない (リソースはいずれもexterms:weight プロパティを持つことができる)。例えば、ドメインとしてex:Bookを指定しているものなど、exterms:weightにドメインプロパティが一つある場合、exterms:weightプロパティはクラスex:Bookのインスタンスに適用するということを意味する。
例えば、ドメインとしてex:Bookを指定しているものと、ex:MotorVehicleを指定しているものなど、exterms:weightに複数のドメインプロパティがある場合、exterms:weight プロパティを持つリソースはいずれもドメインとして指定されているすべてのクラスのインスタンスであることを意味する。例えば、(ドメインと範囲を指定する際に必要な注意を説明して)いずれもex:Book とex:MotorVehicleの両方であるexterms:weightプロパティを持つリソースであるという意味である。
車両スキーマを拡張し、二つのプロパティex:registeredToとex:rearSeatLegRoom、新しいクラスex:Personを追加し、データタイプとしてデータタイプxsd:integer を明示的に記述することによって、上記の範囲とドメインの記述の使用に関して説明することができる。ex:registeredToプロパティは、任意のex:MotorVehicleに適用し、その値は、ex:Personである。この例のために、ex:rearSeatLegRoomは、クラスex:PassengerVehicleのインスタンスだけに適用する。値は、後部座席のレグルームのセンチメートルの数を与えているxsd:integer である。これらの記述は、例
19に示している。
<rdf:Description rdf:ID="registeredTo">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#MotorVehicle"/>
<rdfs:range rdf:resource="#Person"/>
</rdf:Description>
<rdf:Description rdf:ID="rearSeatLegRoom">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#PassengerVehicle"/>
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#integer"/>
</rdf:Description>
<rdf:Description rdf:ID="Person">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/2001/XMLSchema#integer">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Datatype"/>
</rdf:Description>
http://example.org/schemas/vehiclesで特定されている前述の車両スキーマにこのRDF/XMLに追加していると仮定しているため、<rdf:RDF>要素を例
19に使用していないことに注意。 また、この仮定では、#MotorVehicle などのような相対URIrefを使用してそのスキーマからの他のクラスを参照する。
RDFスキーマは、クラスと同様にプロパティを特別化するための方法を提供する。二つのプロパティ間のこの特別関係をあらかじめ定義したrdfs:subPropertyOf プロパティで記述する。例えば、ex:primaryDriverとex:driverのどちらもプロパティである場合、以下のRDFステートメントを作成することによって、これらのプロパティとex:primaryDriverはex:driverの特別化であるということを記述できる。
ex:driver rdf:type rdf:Property .
ex:primaryDriver rdf:type rdf:Property .
ex:primaryDriver rdfs:subPropertyOf ex:driver .
rdfs:subPropertyOfの関係が意味するのは、インスタンスex:fred はインスタンスex:companyVanの ex:primaryDriverであり、 ex:fredも黙示的にex:companyVanのex:primaryDriverであると考えられるということである。これらのプロパティを記述するRDF/XMLを、(再びこれを前述の車両スキーマに追加していると仮定して)例
20に示している。
<rdf:Description rdf:ID="driver">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="primaryDriver">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:subPropertyOf rdf:resource="#driver"/>
</rdf:Description>
プロパティは、0、1、または複数のプロパティであってもよい。RDFプロパティに適用する
RDFrdfs:rangeプロパティとrdfs:domainプロパティもすべてそれぞれのサブプロパティに適用する。そのため、ex:driverへのサブプロパティの関係から、上記の例のex:primaryDriverも黙示的にex:MotorVehicleのrdfs:domainを持つ。
例
21では、今まで述べた記述を含めて、完全な車両スキーマのRDF/XMLを示している。
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xml:base="http://example.org/schemas/vehicles">
<rdf:Description rdf:ID="MotorVehicle">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="PassengerVehicle">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="Truck">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="Van">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="MiniVan">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#Van"/>
<rdfs:subClassOf rdf:resource="#PassengerVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="Person">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/2001/XMLSchema#integer">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Datatype"/>
</rdf:Description>
<rdf:Description rdf:ID="registeredTo">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#MotorVehicle"/>
<rdfs:range rdf:resource="#Person"/>
</rdf:Description>
<rdf:Description rdf:ID="rearSeatLegRoom">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#PassengerVehicle"/>
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#integer"/>
</rdf:Description>
<rdf:Description rdf:ID="driver">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:domain rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="primaryDriver">
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<rdfs:subPropertyOf rdf:resource="#driver"/>
</rdf:Description>
</rdf:RDF>
RDFスキーマを使用してクラスとプロパティの記述の仕方を述べてきたので、これらの記述に対応するインスタンスがどうなっているのかを理解できる。
例えば、例
22では、仮説的なプロパティの値を使って、上記で述べたex:PassengerVehicleクラスのインスタンスについて示している。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/schemas/vehicles">
<rdf:Description rdf:ID="johnSmithsCar">
<rdf:type rdf:resource="http://example.org/schemas/vehicles#PassengerVehicle"/>
<ex:registeredTo rdf:resource="http://www.example.org/staffid/85740"/>
<ex:rearSeatLegRoom
rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">127</ex:rearSeatLegRoom>
<ex:primaryDriver rdf:resource="http://www.example.org/staffid/85740"/>
</rdf:Description>
</rdf:RDF>
このインスタンスはスキーマとは別の文書に記述され、前述の様にスキーマはリソースhttp://example.org/schemas/vehiclesであると想定している。そのため、ネーム空間宣言xmlns:ex="http://example.org/schemas/vehicles"を提供して、そのスキーマを参照する。そして、これは、インスタンスデータがex:registeredTo などの省略形を使用してそのスキーマにに記述されているプロパティを明白に参照できるようにする。しかし、(rdf:resource属性の値としてex:を参照しているQNameを使用することができないので)rdf:typeプロパティを使用してインスタンスのクラスメンバーシップを述べる場合、クラスのフルURIrefを使用して参照しなければならない。
ex:PassengerVehicleはex:MotorVehicleのサブクラスなので、ex:PassengerVehicleのこのインスタンスを記述する際にはex:registeredToプロパティを使用することができるということに注意。また、プレーンなリテラルではなく、ex:rearSetLegRoom プロパティの値の型付き(typed)リテラルを上記の例に使用していることにも注意のこと(例えば、<ex:rearSeatLegRoom>127</ex:rearSeatLegRoom>だとは記述していない)。スキーマはこのプロパティの範囲をxsd:integerとして記述しているので、範囲記述と一致させるためにそのプロパティの値はデータタイプの型付き(typed)リテラルでなければならない(例えば、範囲宣言は、データタイプをプレーンなリテラルに「割り当て」てはいない)。
第3.2節で述べた様に、RDF/XMLシンタックスには、 rdf:typeを使用するクラスのメンバーとして定義されたインスタンスの省略形がある。この省略形を使用すると、この同じインスタンスを例 23の様に記述できる。
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/schemas/vehicles">
<ex:PassengerVehicle rdf:ID="johnSmithsCar">
<ex:registeredTo rdf:resource="http://www.example.org/staffid/85740"/>
<ex:rearSeatLegRoom
rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">127</ex:rearSeatLegRoom>
<ex:primaryDriver rdf:resource="http://www.example.org/staffid/85740"/>
</ex:PassengerVehicle>
</rdf:RDF>
例
23では、クラスはrdf:resource属性の値としてではなく、要素名(ex:PasssengerVehicle)で識別される。そのため、前述の形式で行ったようにフルURIrefとして書くのではなく、QName
ex:PasssengerVehicleで省略することができる
前述の様に、RDFスキーマタイプは、Javaのようなオブジェクト指向のプログラミング言語のタイプシステムにどこか似ている。しかし、ほとんどのプログラミング言語とは重要な面で違う部分がある。
大きな相違点として、特定のプロパティのコレクションを持つものとしてクラスを記述するかわりに、RDFスキーマはドメインプロパティと範囲プロパティを使用してリソースの特定のクラスに適用するものとしてプロパティを記述することがあげられる。例えば、 一般的なオブジェクト指向のプログラミング言語は、タイプPersonの値を持つauthorという属性でクラスBookを定義することがある。対応するRDFスキーマは、 クラスex:Bookを記述し、別々にex:Bookのドメインとex:Personの範囲を持つプロパティex:authorを記述する。
この二つの方法の相違は、構文的だけだと思えるかもしれないが、事実、重要な相違がある。プログラミング言語クラスの記述では、属性authorはクラスBookの記述の一部であり、クラスBookのインスタンスのみに適用する。その他のクラス(例えば、softwareModule)にも、authorという属性があるが、異なる属性だと考えられる。言い換えれば、ほとんどのプログラミング言語での属性記述の範囲は定義されるクラスやタイプに制限されている。反対に、 RDFでは、デフォルトではクラス記述は、(ドメイン仕様を使用して特定のクラスのみに適用すると宣言できる場合もあるが)クラス定義から独立tしていて、グローバルな範囲があるということである。
そのため、例えば、RDFスキーマはドメインを指定せずにプロパティexterms:weightを記述できる。そして、このプロパティは、重さをもっていると考えられる任意のクラスのインスタンスを記述するために使用される。RDFプロパティベースの方法を使用することの利点の一つとして、オリジナルの記述では予想されない状況にまでプロパティ定義の使用の拡張が簡単にできるということがあげられる(もちろん、これはプロパティが不適切な状況に誤適用されないようにするために慎重に使用しなければならない「利点」であるが)。
大きな相違としてもう一つは、RDFスキーマの記述は必ずしもプログラミング言語タイプの宣言の様な方法で規定する必要はない、ということである。例えば、プログラミング言語がクラスBookを、タイプPersonの値を持つauthor属性で宣言する場合、いつも制約の集団であると解釈される。プログラミング言語はauthor属性なしでのBookのインスタンスの作成を許可していないし、値としてPersonのないauthor属性でBook のインスタンスを許可していない。さらに、authorがクラスBookのために唯一定義された属性である場合、プログラミング言語は他の属性でのBookのインスタンスを許可しない。
反対に、RDFスキーマは、スキーマ情報をリソースの追加記述として提供しているが、その記述をアプリケーションがどのように使用するかを指示していない。例えば、RDFスキーマがex:authorプロパティにはクラスex:Personの rdfs:rangeがあると述べているとする。これは単に、ex:authorプロパティを含むRDFステートメントには、目的語 (object) としてex:Personのインスタンスがあるということを意味しているだけである。
このスキーマが提供している情報は、異なる方法でも使用できる。あるアプリケーションでは、このステートメントをRDFデータ作成のテンプレートの一部を定義していると解釈し、これを使用してex:authorプロパティはいずれも指示した(ex:Person) クラスの値を持っていることを保証する。つまり、このアプリケーションはスキーマ記述をプログラミング言語が行っているのと同じ様に制約として解釈する。しかし、別のアプリケーションは、このステートメントを受信しているデータについての追加情報を提供しており、明示的にオリジナルのデータには提供されていないと解釈するかもしれない。例えば、二番目のアプリケーションは、指定されていないクラスのリソースが値であるex:authorプロパティを含むRDFデータの一部を受信し、このスキーマで提供されたステートメントを使用してそのリソースはクラスex:Personのインスタンスであるに違いないと結論付けることもできる。三番目のアプリケーショは、クラスex:Corporationのリソースを値とする ex:authorプロパティを含むRDFデータの一部を受信し、このスキーマ情報を「不整合があるかも知れないがないかもしれない」という警告の根拠として使用するかもしれない。明白な不整合を解決する宣言がどこかにある可能性がある(例えば、「会社は(合法的な)人である」という要点への宣言など)。
さらに、アプリケーションがプロパティ記述をどのように解釈するかにもよるが、インスタンスの記述は、スキーマが指定したプロパティの一部がない場合(例えば、ex:authorがex:Bookのドメインを持つと記述されていたとしてもex:authorプロパティのないex:Bookのインスタンスを持つことができる)や、追加のプロパティがある場合(例えば、特別なスキーマでは記述していなくてもex:technicalEditorプロパティでex:Book のインスタンスを記述できる)でもインスタンスの記述は有効であるとみなすことができる。
言い替えれは、RDFスキーマのステートメントはいつも記述である、ということである。また、(制約を誘発する)指示である場合もあるが、それは、ステートメントを解釈するアプリケーションがそうするように処理を行う場合に限る。RDFスキーマはすべてこの追加情報を述べる方法を提供するものである。この情報が明示的に指定されているインスタンスデータと矛盾するかどうかは、決定や動作を行うアプリケーションによる。
RDFスキーマは、他にもプロパティを提供する。そのプロパティは、RDFスキーマやインスタンスに関する文書やその他の情報を提供するために使用できるものである。例えば、rdfs:commentプロパティを使用して人間が読むことのできるリソースの記述ができる。 rdfs:labelプロパティを使用すれば、リソースのより人間が読むことのできるバージョンを提供できる。rdfs:seeAlsoプロパティは、主語 (subject)リソースについての詳細情報を提供できるリソースを示すために使用できる。 rdfs:isDefinedByプロパティは、rdfs:seeAlsoのサブプロパティであり、主語 (subject)リソースを「定義」するリソースを示すために使用できる(RDFでは指定されない部分。例えば、リソースはRDFスキーマにはなれない)。これらのプロパティの関しての詳細は、RDF Vocabulary Description Language 1.0: RDF Schema [RDF-VOCABULARY]を参照こと。
RDFスキーマには、RDFボキャブラリを記述するための基本的な機能が備わっているが、付加的な機能も可能なので便利である。これらの機能はRDFスキーマの更なる開発を通して提供される、他の言語でも提供できる。便利なものとして認識されているより豊富なスキーマ機能(しかし、RDFスキーマにはない)には、以下がある
- プロパティの濃度の制約例えば、人には、血のつながった父親が一人 いる。
- 任意のプロパティ(hasAncestorなどを)他動詞的だと指定すること。例えば、A hasAncestor B、とB hasAncestor Cの場合、A hasAncestor Cである。
- 任意のプロパティを特定のクラスのインスタンスの一意の識別子(または、 key)と指定すること。
- (異なるURIrefを持つ)二つの異なるクラスが実際は同じコンセプトを表現していると指定すること。
- (異なるURIrefを持つ)二つの異なるインスタンスが実際は同じ個人を表現していると指定すること。
- 他のクラスの組み合わせに関して新しいクラスを記述したり(例えば、結びと交わり)、二つのクラスは交わらないと述べる(例えば、リソースは二つのクラスのインスタンスではない)機能。
他の機能に平行して、上記の詳細機能は、DAML+OIL [DAML+OIL] とOWL [OWL]などのオントロジー言語の対象である。
これらの言語は、RDFとRDFスキーマに準拠している (両方とも上記の機能をすべて備えている)。これらの言語の目的は、リソースのマシンが処理することのできる セマンティックをさらに提供することである。つまり、リソースのマシン表現を現実世界の意図したものにより近づけることである。 こういった機能はRDF(現行のRDFアプリケーションの記述については第6節を参照のこと)を使用して便利なアプリケーションを必ずしも構築する必要はないが、こういった言語の開発は、セマンティックWebの開発の一環として作業においての非常に議論が活発なテーマである。
6. RDFアプリケーション: 現在のRDF
前節では、RDFとRDFスキーマの一般的な機能について述べた。この機能を説明するために前節では例を使用した。その中には、RDFの応用の可能性を述べたものもあり、実際の応用について述べていないものもある。本節では、様々な物事についての情報を表現し、操作するために、RDFがどのように実際の世界での要件に対応しているかを説明しながら、実際に導入されたRDFアプリケーションをいくつか紹介する。
メタデータとは、データについてのデータのことである。特にこの用語は、リソースが物理的であっても電子であっても、その情報リソースの識別、記述、検索を行うために使用されるデータを意味する。コンピュータで処理された構造化されたメタデータは比較的新しく、メタデータの基本概念は長年、情報の大収集を管理し、使用するのに役に立つ中で使用されてきた。こういったメタデータの例としておなじみなのが図書館カードのカタログがある。
Dublin Coreとは、文書を記述するための「要素(プロパティ)」のセットのことである(そのため、メタデータを記録する)。要素セットはもともとオハイオのダブリンにある1995年3月メタデータワークショップで開発された。Dublin Coreは、後の Dublin Core メタデータワークショップを元に変更されたもので、現在、はDublin Core Metadataイニシアチブで保持されている。Dublin Coreの目的は、文書のようなネットワーク化された目的語 (object) の記述と自動索引を容易にする記述的な要素のセットを図書カードカタログに似た方法で最小限に提供することである。Dublin Coreメタデータセットは、 一般に使用されているワールド・ワイド・ウェブ検索エンジンで採用している"webcrawlers"などの、インテーネット上のリソース発見ツールが使用するのに適したものとすることを目的としている。さらに、Dublin Coreは、インターネット上で情報を提供する広範囲な著者や臨時の発行者が理解し使用するのに十分に簡単であることを目標としている。Dublin Core要素はインターネットリソースの文書化で広く使用されるようになってきた (すでに前述の例でもDublin Coreの creator要素が使用されている)。Dublin Coreの現在の要素は、.Dublin Coreメタデータ要素セット、バージョン1.1: 参照記述 [DC]で定義され、以下のプロパティの定義が含まれている。
- Title: リソースへ与えられた名前。
- Creator: リソースのコンテンツを作成することを第一の責務としている実体。
- Subject: リソースのコンテンツのトピック。
- Description: リソースのコンテンツのアカウント。
- Publisher: リソースを使用できるようにする責任がある実体。
- Contributor: リソースのコンテンツに貢献する責任がある実体。
- Date: リソースの有効期限のイベントに関する日付。
- Type: リソースのコンテンツの性質や様式
- Format: リソースの物理的で数字の表明。
- Identifier: 任意のコンテンツ内でのリソースへの明白な参照。
- Source: 現在のリソースが発生しているリソースへの参照。
- Language: リソースの知的コンテンツの言語
- Relation: 関連するリソースへの参照。
- Coverage: リソースのコンテンツの範囲。
- Rights: リソースが保有している権利についての情報。
Dublin Core要素を使用した情報は適切な言語で表現できる(例えば、HTMLメタ要素など)。しかし、RDFは、Dublin Core情報の望ましい表現である。以下の例では、Dublin Coreボキャブラリを使用してRDFでのリソースのセットの簡単な記述を示す。ここで示している特定のDublin Core RDFボキャブラリは、信頼できるものであることを目的としてはいない。Dublin Core 参照記述[DC]
は、信頼できる参照である。
最初の例、例
24では、Dublin Coreプロパティを使用したWebサイトのホームページを示している。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://www.dlib.org">
<dc:title>D-Lib Program - Research in Digital Libraries</dc:title>
<dc:description>The D-Lib program supports the community of people
with research interests in digital libraries and electronic
publishing.</dc:description>
<dc:publisher>Corporation For National Research Initiatives</dc:publisher>
<dc:date>1995-01-07</dc:date>
<dc:subject>
<rdf:Bag>
<rdf:li>Research; statistical methods</rdf:li>
<rdf:li>Education, research, related topics</rdf:li>
<rdf:li>Library use Studies</rdf:li>
</rdf:Bag>
</dc:subject>
<dc:type>World Wide Web Home Page</dc:type>
<dc:format>text/html</dc:format>
<dc:language>en</dc:language>
</rdf:Description>
</rdf:RDF>
(Dublin Core要素名は小文字だが)RDFとDublin Coreは両方とも、"Description"という(XML)要素を定義することに注意。最初の文字が同様に大文字であっても、XMLネーム空間メカニズムを使用すると、これら二つの要素を区別できる(一つはrdf:Description、もう一つは、 dc:description)。また、重要な事柄として、Webブラウザでhttp://purl.org/dc/elements/1.1/にアクセスする場合(現行の文書において)、 [DC]のRDFスキーマ宣言を取得する。
次の例、例
25では、発刊された雑誌について述べる。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:dcterms="http://purl.org/dc/terms/">
<rdf:Description rdf:about="http://www.dlib.org/dlib/may98/05contents.html">
<dc:title>DLIB Magazine - The Magazine for Digital Library Research
- May 1998</dc:title>
<dc:description>D-LIB magazine is a monthly compilation of
contributed stories, commentary, and briefings.</dc:description>
<dc:contributor>Amy Friedlander</dc:contributor>
<dc:publisher>Corporation for National Research Initiatives</dc:publisher>
<dc:date>1998-01-05</dc:date>
<dc:type>electronic journal</dc:type>
<dc:subject>
<rdf:Bag>
<rdf:li>library use studies</rdf:li>
<rdf:li>magazines and newspapers</rdf:li>
</rdf:Bag>
</dc:subject>
<dc:format>text/html</dc:format>
<dc:identifier rdf:resource="urn:issn:1082-9873"/>
<dcterms:isPartOf rdf:resource="http://www.dlib.org"/>
</rdf:Description>
</rdf:RDF>
例
25では、(最後から三行目に)Dublin Core
修飾子 isPartOf (別のネーム空間からの) を使用して、この雑誌は前述のWebサイトの「一部」であるということを示している。
三つ目の例、例
26では、例
25で記述した雑誌にある特定の記事について述べている。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:dcterms="http://purl.org/dc/terms/">
<rdf:Description rdf:about="http://www.dlib.org/dlib/may98/miller/05miller.html">
<dc:title>An Introduction to the Resource Description Framework</dc:title>
<dc:creator>Eric J. Miller</dc:creator>
<dc:description>The Resource Description Framework (RDF) is an
infrastructure that enables the encoding, exchange and reuse of
structured metadata. rdf is an application of xml that imposes needed
structural constraints to provide unambiguous methods of expressing
semantics. rdf additionally provides a means for publishing both
human-readable and machine-processable vocabularies designed to
encourage the reuse and extension of metadata semantics among
disparate information communities. the structural constraints rdf
imposes to support the consistent encoding and exchange of
standardized metadata provides for the interchangeability of separate
packages of metadata defined by different resource description
communities. </dc:description>
<dc:publisher>Corporation for National Research Initiatives</dc:publisher>
<dc:subject>
<rdf:Bag>
<rdf:li>machine-readable catalog record formats</rdf:li>
<rdf:li>applications of computer file organization and
access methods</rdf:li>
</rdf:Bag>
</dc:subject>
<dc:rights>Copyright @ 1998 Eric Miller</dc:rights>
<dc:type>Electronic Document</dc:type>
<dc:format>text/html</dc:format>
<dc:language>en</dc:language>
<dcterms:isPartOf rdf:resource="http://www.dlib.org/dlib/may98/05contents.html"/>
</rdf:Description>
</rdf:RDF>
例26では、修飾子 isPartOfを使用している。この場合は、この記事が前述の雑誌の「一部」であるとくことを示している。
PRISM:
Publishing Requirements for Industry Standard Metadata(業界標準メタデータの発行要件) [PRISM]
とは、出版業界で開発されたメタデータの仕様のことである。雑誌発行者とその業者は、PRISMワーキンググループを結成してメタデータの出版業界のニーズを特定し、そのニーズに合うように仕様を定義した。発行者は、作成時の投資に対してより多くの利益を得るため、様々な方法で既存のコンテンツを使用したいと考える。雑誌の記事をWeb上に置くためにHTMLに変換することもその一つの例である。LexisNexisなどのように、その記事の仕様許諾を集積者に与えることは別の例である。これらはすべて、コンテンツの「最初の使用」であり、一般的に、雑誌が発売されるときに稼動する。また、発行者は、その内容がいつまでも新鮮であってほしいと考える。回顧的記事としてその内容が新しい問題で使用されることもあるかもしれない。雑誌の写真やレシピなどから編集した本のように、その会社の別の部門で使用されることもある。別の使用としては、外部にその内容の使用許諾を与えるというものもある。例えば、製品レビューの再印刷や異なる発行者によって作成された回顧的なものなど。この全体的な目的には、discovery(発見)やrights tracking(権利追求)、,end-to-end metadata(エンド・ツー・エンドのメタデータ)を重視するメタデータ・アプローチが必要である。
Discovery(発見): Discovery(発見)とは、検索、ブラウジング、コンテンツルーティング、やその他の技術で網羅するコンテンツを検索するための一般的な用語である。Discovery(発見)は、公的なWebサイトを検索する消費者で間で頻繁に中心となる話題である。。しかし、コンテンツの発見はそれ以上に広範囲である。読者は、消費者で構成されることもあるし、研究者やデザイナー、写真編集者、ライセンシングエージェントなどの内部ユーザで構成されることもある。発見を支援するために、PRISMはプロパティを提供してリソースのトピックや形式、様式、起点、コンテキストなどを記述する。また、複数の主語 (subject)記述分類を使用して、リソースの分類の方法も提供する。
Rights Tracking(権利追求):雑誌には頻繁に他から使用許諾を受けた資料が含まれている。 ストック・フォト・エージェンシーからの写真は最もよく見られるタイプの使用許諾を受けた資料であるが、記事、補助的な内容、そしてその他の種類の内容は使用許諾をうけることができる。単に、ある内容の一度だけの使用に許諾があるかどうかを知る場合、ロイヤリティの支払いが必要であるし、発行者が完全に所有している内容は紛争の原因となる。PRISM はそういった権利の基本的な追求のための要素を提供する。PRISM仕様書で定義されている別のネーム空間(ボキャブラリ)は、内容が使用できなりできなかったりする場所、時間、業界に対応している。
End-to-end metadata(エンド・ツー・エンドのメタデータ):発行されているコンテンツのほとんどにはすでに、そのコンテンツ用に作成されたメタデータがある。残念ながら、システム間でコンテンツが移動すると、メタデータは破棄され、後で生産過程で再作成するにはかなりの費用がかかる。PRISMは、コンテンツ生産パイプラインでの複数の段階で使用できる仕様を提供してこの問題を軽減することを目的としている。 PRISM仕様の重要な特徴は、他の既存の仕様を使用することである。グループは、全く新しいものを作成するのではなく、できるだけ既存の仕様を使用し、必要な場合に新しいことを定義するということを決定した。このため、PRISM仕様は、さまざまなISO形式やボキャブラリと同様にXML、RDF、Dublin Coreを使用する。
PRISM仕様は、プレーンなリテラル値でいくつかのDublin Coreプロパティと同じくらい簡単かもしれない。例
27では、タイトル、写真家、形式などに関する基本情報を提供して写真について述べている。
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:lang="en-US">
<rdf:Description rdf:about="http://wanderlust.com/2000/08/Corfu.jpg">
<dc:title>Walking on the Beach in Corfu</dc:title>
<dc:description>Photograph taken at 6:00 am on Corfu with two models
</dc:description>
<dc:creator>John Peterson</dc:creator>
<dc:contributor>Sally Smith, lighting</dc:contributor>
<dc:format>image/jpeg</dc:format>
</rdf:Description>
</rdf:RDF>
また、PRISMは、より詳細な記述ができるようにするため、Dublin Coreを補強する。この補強は、プリフィックス(接頭辞)prism:、pcv:、prl:を使用して一般的に引用されている三つの新しいネーム空間で定義されている。
prism:このプリフィックス(接頭辞)は、URIが
http://prismstandard.org/namespaces/basic/1.0/である主なPRISMネーム空間を参照する。そのプロパティのほとんどはDublin Coreからのプロパティのより特定のバージョンである。例えば、dc:dateのより特定なバージョンは、prism:publicationTime、prism:releaseTime、prism:expirationTime、などのようなプロパティで提供されている
pcv:このプリフィックス(接頭辞)は、URIがhttp://prismstandard.org/namespaces/pcv/1.0/である PRISMで制御されたボキャブラリ(PRISM Controlled Vocabulary )ネーム空間を参照する。現在、記事の表題を記述する一般的な方法は、記述的なキーワードを入力することによって行われる。別々の人が別々のキーワード[BATES96]を使用するという事実があるため、残念ながら、簡単なキーワードでは検索性能に大きな違いは見られない。
最善の方法は、「制御されたボキャブラリ」からの表題用語で記事を符号化することである。ボキャブラリは、ボキャブラリにおけるその用語に対し同義語をできるけ多く提供する必要がある。このようにして、制御された用語は、検索者や索引者が提供したキーワードが集まる場所を提供する。PRISMで制御された(pcv) (PRISM Controlled Vocabulary )ネーム空間は、ボキャブラリに用語を指定するためのプロパティ、用語間の関係、その用語の代わりとなる名前を提供する
prl:このプリフィックス(接頭辞)は、URIがhttp://prismstandard.org/namespaces/prl/1.0/であるPRISM権利言語(PRISM Rights Language)ネーム空間を参照する。デジタル権利管理(Digital Rights Management)は、非常に激動を受けている分野である。権利管理言語の提案がたくさんあるが、業界ではどれがいいのかがはっきりしていない。推奨するのにはっきりとした選択がないので、PRL (PRISM Rights Language‐PRISM権利言語‐)が暫定的な方法として定義されている。PRLは、時間や、地理、産業によって項目が「使用」できるかできないかを述べることができるようにするプロパティを提供する。これは、発行者が権利追及の際にお金を節約し始めるのに役立つ80/20トレードオフであると考えられており、一般的な権利言語を意図したものでもなければ、発行者が自動的に消費者のコンテンツ使用を制限するためのものでもない。
様々に複雑なものの記述を扱う機能により、PRISMは、RDFを使用する。現在、多大なメタデータでは簡単な文字列(プレーンなリテラル)値が使用されている。例えば、以下のようなものである。
<dc:coverage>Greece</dc:coverage>
長期的に、PRISMの開発者は、簡単なリテラル値からより構造化された値に移行して、PRISM仕様を使用することがより複雑になると予測している。事実、値の範囲は、そういったことに直面している。発行者の中には、すでに複雑で制御されたボキャブラリを使用しているものもいるが、手動で提供されたキーワードを使用しているものもわずかにいる。これを説明するために、 coverageプロパティに与えられている異なる値の例をいくつか以下に述べる。
<dc:coverage>Greece</dc:coverage>
<dc:coverage rdf:resource="http://prismstandard.org/vocabs/ISO-3166/GR"/>
(つまり、プレーンなリテラル、または、URIrefを使用している)
<dc:coverage>
<pcv:Descriptor rdf:about="http://prismstandard.org/vocabs/ISO-3166/GR">
<pcv:label xml:lang="en">Greece</pcv:label>
<pcv:label xml:lang="fr">Grece</pcv:label>
</pcv:Descriptor>
</dc:coverage>
(構造化された値を使用している)
また、意味が同じであるプロパティや他のプロパティのサブセットがあることに注意。例えば、リソースの地理的主語 (subject)は、以下で与えられる。
<prism:subject>Greece</prism:subject>
<dc:coverage>Greece</dc:coverage>
または、
<prism:location>Greece</prism:location>
これらのプロパティはいずれも、同じリテラル値か、より複雑な構造化された値を使用することがある。そういった可能性は、DTDや、より新しいXMLスキーマ適切に述べることはできない。対処するための構文的な変化の範囲は広いが、RDFのグラフモデルには、簡単な構造‐トリプルのセット‐がある。トリプルドメインでのメタデータの処理によって、旧式のソフトウェアは非常に簡単に新しい識別子でコンテンツを収容できる。
最後に二つの例を提示してこの節を終わる。 例28では、画像(.../Corfu.jpg)は、たばこ産業(SIC, Standard Industrial Classificationsのコード 21)で使用できない(#none)ことを示している。
<rdf:RDF xmlns:prism="http://prismstandard.org/namespaces/basic/1.0/"
xmlns:prl="http://prismstandard.org/namespaces/prl/1.0/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://wanderlust.com/2000/08/Corfu.jpg">
<dc:rights rdf:parseType="Resource"
xml:base="http://prismstandard.org/vocabularies/1.0/usage.xml">
<prl:usage rdf:resource="#none"/>
<prl:industry rdf:resource="http://prismstandard.org/vocabs/SIC/21"/>
</dc:rights>
</rdf:Description>
</rdf:RDF>
例
29では、 Corfu画像の写真家は、John Petersonで知られている従業員3845であることを示している。また、写真の地理的範囲はギリシャであることも述べている。制御されているボキャブラリからのコードだけではなく、ボキャブラリの用語のための情報のキャッシュされたバージョンも提供して、上記のことを述べている。
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pcv="http://prismstandard.org/namespaces/pcv/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:base="http://wanderlust.com/">
<rdf:Description rdf:about="/2000/08/Corfu.jpg">
<dc:identifier rdf:resource="/content/2357845" />
<dc:creator>
<pcv:Descriptor rdf:about="/emp3845">
<pcv:label>John Peterson</pcv:label>
</pcv:Descriptor>
</dc:creator>
<dc:coverage>
<pcv:Descriptor
rdf:about="http://prismstandard.org/vocabs/ISO-3166/GR">
<pcv:label xml:lang="en">Greece</pcv:label>
<pcv:label xml:lang="fr">Grece</pcv:label>
</pcv:Descriptor>
</dc:coverage>
</rdf:Description>
</rdf:RDF>
多くの場合、一つの単位として使用されるリソースの構造化されたグループ化やその関係についての情報を保持する必要がある。 XML Package (XPackage) 仕様 [XPACKAGE] は、パッケージというそういったグループを定義するフレームワークを提供する。XPackageは、そのパッケージに含まれるリソースや、そのリソースのプロパティ、その含有方法、それらの関係を記述するためのフレームワーク指定する。XPackageアプリケーションには、文書で使用するスタイルシートの指定や、複数の文書で共有する画像の宣言、文書の著者やその他のメタデータの描写や、XMLリソースがどのようにネーム空間を使用するのかの記述、一つのアーカイブファイルにリソースをバンドルするための明細を提供することなどが含まれる。
XPackageフレームワークは、XML、RDF、XML Linking Language [XLINK],
に準拠しており、二つのRDFボキャブラリを提供する。一つは、一般的なパッケージング記述で、もう一つは、XMLリソースを記述する特別なものである。また、XPackageフレームワークは、拡張/制限でカスタマイズが可能である。
XPackageの応用の一つに、XHTML文書の記述とそのリソースのサポートがある。Webサイトから検索されたXHTML 文書は、検索され必要のあるスタイルシートや画像ファイルなど、他のリソースに依存する。しかし、サポートしているこれらのリソースの独自性は、全文書を処理しないと明白にはできない。著者の名前など文書の他の情報も文書を処理しないと利用できない。XPackageを使用すると、そういった記述的な情報を、RDFを含むパッケージ記述文書に標準的な方法で格納することができる。そういったXHTMLを記述しているパッケージ記述文書の他の要素は、例
30 (簡単にするために、ネーム空間宣言を削除している)の様になる。
<?xml version="1.0"?>
<xpackage:description>
<rdf:RDF>
(description of individual resources go here)
</rdf:RDF>
</xpackage:description>
(XHTML文書や、スタイルシート、画像など)リソースはこのパッケージ記述文書に記述される。XHTML文書のリソースはそれ自身、(用語XPackageがボキャブラリ用に使用する)XPackageオントロジーからのRDFリソース記述要素<xpackage:resource>を使用して記述される。各リソース記述要素には、様々なオントロジーからのRDFプロパティを含めることができる。例 31では、文書のMIMEコンテンツタイプ (「アプリケーション/xhtml+xml」)は、XPackageオントロジー xpackage:contentTypeからの標準的なXPackageを使用して定義されている。もう一つのプロパティ、文書の著者(この場合、"Garret Wilson")は、(XPackageのカスタムオントロジー(custom ontology)だと考えられている)Dublin Coreからのプロパティを使用して記述され、dc:creatorプロパティとなる。XPackageそれ自身、特に、 それぞれxmlprop:namespaceやxmlprop:styleでのXMLネーム空間やスタイルシートの指定を含む、XMLべースのリソースや、XMLオントロジー用に拡張プロパティセットを指定する。
<!--doc.html-->
<xpackage:resource rdf:about="urn:examples:xhtmldocument-doc">
<rdfs:comment>The XHTML document.</rdfs:comment>
<xpackage:location xlink:href="doc.html"/>
<xpackage:contentType>application/xhtml+xml</xpackage:contentType>
<xmlprop:namespace rdf:resource="http://www.w3.org/1999/xhtml"/>
<xmlprop:style rdf:resource="urn:examples:xhtmldocument-stylesheet"/>
<xmlprop:annotation rdf:resource="urn:examples:xhtmldocument-annotation"/>
<dc:creator>Garret Wilson</dc:creator>
<xpackage:manifest>
<rdf:Bag>
<rdf:li rdf:resource="urn:examples:xhtmldocument-stylesheet"/>
<rdf:li rdf:resource="urn:examples:xhtmldocument-image"/>
</rdf:Bag>
</xpackage:manifest>
</xpackage:resource>
xpackage:manifestプロパティは、スタイルシートリソースと画像リソースが処理に必要であるということを示している。これらのリソースはパッケージ記述文書内で別々に記述されている。例
32で示しているスタイルシートリソースの記述の例では、(XLinkと互換性のある)XPackageオントロジープロパティxpackage:locationプロパティを使用してその場所(「stylesheet.css」)をリストし、CSSスタイルシート(「text/css」)であるXPackageオントロジーxpackage:contentTypeプロパティの使用について示している。
<!--stylesheet.css-->
<xpackage:resource rdf:about="urn:examples:xhtmldocument-css">
<rdfs:comment>The document stylesheet.</rdfs:comment>
<xpackage:location xlink:href="stylesheet.css"/>
<xpackage:contentType>text/css</xpackage:contentType>
</xpackage:resource>
この例の完全版は[XPACKAGE]で参照できる。
例えば、スケジュール、作業のリスト、ニュースのヘッドライン、検索結果、「今日の出来事」など、毎日のWebへアクセスする情報のすべてを考える場合、こういった情報を管理し、情報増大のソースや多様性として整合性のある一体に統合することはますます難しくなってくる。RSS 1.0 (「RDFサイトサマリ」) とは、軽量で多目的な拡張性あるメタデータ記述と独立の形式を提供する。つまり、RSS 1.0とは、幅広い読者に適切でタイムリーな情報を記述、管理、利用できるようにするための強力で拡張性のある方法である。RSS1.0を使用すると、この情報を豊富で再利用できる方法で利用でき、恐らく、Web上で最も広く導入されているRDFアプリケーションであるといえる。
簡単な例として、 図 18で示しているW3Cホームページが一般の人たちとの連絡の重要なポイントであり、コンソーシアムの配布物についての情報を広めていることを取り上げる。新規項目の真ん中のコラムは頻繁に変更される。この情報のタイムリーな配布に対応するために、W3Cチームは、真ん中のコラムを他の人が利用できるようにするRDFサイトサマリ(RSS 1.0) ニュースフィードを実装している。ニュースのシンジケートサイトは、ヘッドラインをその日の最新ニュースにマージし、その他は、ヘッドラインを読者へのサービスとしてリンクで表示し、ますます個人がこのフィードをデスクトップで申し込みできるようにしている。これらのデスクトップ RSSリーダを使用すると、ブラウザでいちいち訪れなくてもユーザは何百ものサイトを記録することができる。
Webの多くのサイトには、RSS 1.0フィードがある。例
33は、W3Cフィードの例である。
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF xmlns="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<channel rdf:about="http://www.w3.org/2000/08/w3c-synd/home.rss">
<title>The World Wide Web Consortium</title>
<description>Leading the Web to its Full Potential...</description>
<link>http://www.w3.org/</link>
<dc:date>2002-10-28T08:07:21Z</dc:date>
<items>
<rdf:Seq>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item164"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item168"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item167"/>
</rdf:Seq>
</items>
</channel>
<item rdf:about="http://www.w3.org/News/2002#item164">
<title>User Agent Accessibility Guidelines Become a W3C
Proposed Recommendation</title>
<description>17 October 2002: W3C is pleased to announce the
advancement of User Agent Accessibility Guidelines 1.0 to
Proposed Recommendation. Comments are welcome through 14 November.
Written for developers of user agents, the guidelines lower
barriers to Web accessibility for people with disabilities
(visual, hearing, physical, cognitive, and neurological).
The companion Techniques Working Draft is updated. Read about
the Web Accessibility Initiative. (News archive)</description>
<link>http://www.w3.org/News/2002#item164</link>
<dc:date>2002-10-17</dc:date>
</item>
<item rdf:about="http://www.w3.org/News/2002#item168">
<title>Working Draft of Authoring Challenges for Device
Independence Published</title>
<description>25 October 2002: The Device Independence
Working Group has released the first public Working Draft of
Authoring Challenges for Device Independence. The draft describes
the considerations that Web authors face in supporting access to
their sites from a variety of different devices. It is written
for authors, language developers, device experts and developers
of Web applications and authoring systems. Read about the Device
Independence Activity (News archive)</description>
<link>http://www.w3.org/News/2002#item168</link>
<dc:date>2002-10-25</dc:date>
</item>
<item rdf:about="http://www.w3.org/News/2002#item167">
<title>CSS3 Last Call Working Drafts Published</title>
<description>24 October 2002: The CSS Working Group has
released two Last Call Working Drafts and welcomes comments
on them through 27 November. CSS3 module: text is a set of
text formatting properties and addresses international contexts.
CSS3 module: Ruby is properties for ruby, a short run of text
alongside base text typically used in East Asia. CSS3 module:
The box model for the layout of textual documents in visual
media is also updated. Cascading Style Sheets (CSS) is a
language used to render structured documents like HTML and
XML on screen, on paper, and in speech. Visit the CSS home
page. (News archive)</description>
<link>http://www.w3.org/News/2002#item167</link>
<dc:date>2002-10-24</dc:date>
</item>
</rdf:RDF>
例
33で示した様に、形式は簡単に区別ができる節にパッケージできるコンテンツのために設計されている。ニュースのサイト、Webのロゴ、スポーツのスコア、 株価、などはすべてRSS 1.0の使用事例である。
RSSフィードは、HTTPを「話す」ことができるアプリケーションでリクエストできる。しかし、近頃、 RSS 1.0のアプリケーションは三つのカテゴリに分類される。
- オンライン収集者 - 図 19のようなMeerkat やNewsIsFreeなどのようなサイト(ニュースのW3Cコラムのニュースの各々をミラーリングする)。これらは、何千ものソースからフィードを収集し、それぞれを <item>で区切り、一つの大きなグループに再び追加する。 そして、全グループを検索可能にする。このような方法で、最新のニュースを、例えば、"Java"などで、全部のサイトを検索しなくても何千ものサイトから検索することができる。
- デスクトップリーダ - AmphetadeskやNetNewsWire Liteなど、ユーザがデスクトップから何百ものフィードを申し込むことができるユーティリテイ。 リーダは、ユーザを最新に情報を提供でき、一時間に一度各フィールドを更新する。
- スクリプト - RSSの元来の目的は、Webマスターが自身のサイトに著者のコンテンツを組み込むことができるようにすることであった。RSS 1.0 は、今でも、フロントページにRSSフィードを組み込んでいる多くのサイトでこの様に使用されている。(例えば、Slashdotなど )
RSS 1.0 はデザインでは拡張可能である。他のRDFボキャブラリ(または、RSS開発コミュニティ内で知られているモジュール)をインポートすることによって、
RSS 1.0の著者は多数のメタデータや取り扱い上の注意事項をファイルの受信者に提供することができる。より一般的なRDFで、モジュールは誰でもが作成できる。現在、三つの公式モジュールとコミュニティ全体ですぐに承認される19の提案されたモジュール がある。これらのモジュールは、完全なDublin
Core モジュールから、集合モジュール(Aggregation module)などのようなより専門化されたRSS中心のモジュールまでに及んでいる。
「RSS」をRDFの範囲だとする場合は、注意が必要である。現在、二つのRSS仕様ストランドがある。一つ(RSS 0.91、0.92、0.93、0.94 と
2.0)は、RDFを使用しない。もう一つ(RSS 0.9 と 1.0)はRDFを使用する。
6.5 CIM/XML
電子ユーティリティは、いろんな目的でパワーシステムモデルを使用する。例えば、パワーシステムのシミュレーションは、計画やセキュリティ分析で必要である。また、パワーシステムモデルは、実際の操作で使用されている。例えば、エネルギーコントロールセンターで使用されているEMS(電力管理システム‐Energy Management Systems‐) など。操作上のパワーシステムモデルは、何千ものクラスの情報で構成することができる。社内でのこれらのモデルの使用に加え、ユーティリティは、計画においても、操作上の目的でもシステムモデリング情報を交換する必要がある。例えば、送信の調整や確実な操作を保障するため、など。しかし、個々のユーティリティは、これらの目的のために異なるソフトウェアを使用するので、システムモデルは異なる形式で格納され、モデルの交換が困難になる
パワーシステムモデルの交換をサポートするために、ユーティリティはパワーシステムの団体での共通の定義や関係に同意する必要があった。これに対応するために、非営利のエネルギー研究コンソーシアム、Electric Power Research
Institute が CIM (共通情報モデル‐Common Information Model-)を開発した。CIM は、パワーシステムリソース、その属性、そして、関係のための共通のセマンティックを指定している。さらに、CIMモデルをコンピュータ上で交換するための機能をより深くサポートするために、電力業界では、XMLでCIMモデルを表現するための言語、CIM/XML、を開発した。CIM/XMLとは、RDFとRDFスキーマを使用したRDFアプリケーションであり、そのXML構造を編成する。NERC (電気信頼性評議会‐North American
Electric Reliability Council‐) (業界で支持されている組織で、北米の電気配送の信頼性を促進するために設立された)は、CIM/XMLを電力配信システムオペレータ間でモデルを交換するための基準として採用した。CIM/XMLの形式は、 IECの国際基準化プロセスを通過する。CIM/XMLにする詳細は、[DWZ01]で参照できる。
[注意: この電力業界のCIMを、DMTFが開発した配布されたソフトウェアやネットワーク、エンタープライズ環境の管理情報を定義するCIMと混同してはいけない。DMTFのCIMにもXML表現があるが、RDFを使用してはいない]
CIMは、電気事業の主なオブジェクトすべてを目的語 (object) クラスや属性として、その関係と一緒に表現できる。CIMは、目的語 (object) クラスや属性を使用してベンダー専用のEMSシステム間や、EMSシステムと発電や流通管理などの電力システム操作の別の側面に関連するその他のシステム間での独立して開発したアプリケーションの連携をサポートする。
CIMは、UML(Unified Modeling Language )を使用してクラスの図表のセットして指定される。CIMの基本のクラスは、PowerSystemResourceクラスで、Substation、Switch、Breakerなどのより特定したクラスをサブクラスとして有している。CIM/XMは、CIMをRDFスキーマボキャブラリとして表現し、RDF/XMLを特定のシステムモデルを交換するための言語として使用する。例
34では、 CIM/XMLクラスとプロパティ定義の例を示している。
<rdfs:Class rdf:ID="PowerSystemResource">
<rdfs:label xml:lang="en">PowerSystemResource</rdfs:label>
<rdfs:comment>"A power system component that can be either an
individual element such as a switch or a set of elements
such as an substation. PowerSystemResources that are sets
could be members of other sets. For example a Switch is a
member of a Substation and a Substation could be a member
of a division of a Company"</rdfs:comment>
</rdfs:Class>
<rdfs:Class rdf:ID="Breaker">
<rdfs:label xml:lang="en">Breaker</rdfs:label>
<rdfs:subClassOf rdf:resource="#Switch" />
<rdfs:comment>"A mechanical switching device capable of making,
carrying, and breaking currents under normal circuit conditions
and also making, carrying for a specified time, and breaking
currents under specified abnormal circuit conditions e.g. those
of short circuit. The typeName is the type of breaker, e.g.,
oil, air blast, vacuum, SF6."</rdfs:comment>
</rdfs:Class>
<rdf:Property rdf:ID="Breaker.ampRating">
<rdfs:label xml:lang="en">ampRating</rdfs:label>
<rdfs:domain rdf:resource="#Breaker" />
<rdfs:range rdf:resource="#CurrentFlow" />
<rdfs:comment>"Fault interrupting rating in amperes"</rdfs:comment>
</rdf:Property>
CIM/XMLは、モデルのシリアライゼーションを簡単にするために、完全なRDF/XMLのサブセットのみを使用する。さらにCIM/XMLは、(cims:ネーム空間で定義された)RDFスキーマボキャブラリへの拡張を実装して、逆の役割とCIM UMLの図からの任意のリソースのためにいくつの任意のプロパティのインスタンスが許可されるのかを記述する多様性(濃度)をサポートする(多様性に許可される値は、0、または、1、ちょうど1、0以上、1以上である)。例
35のプロパティはこれらの拡張を示す。
<rdf:Property rdf:ID="Breaker.OperatedBy">
<rdfs:label xml:lang="en">OperatedBy</rdfs:label>
<rdfs:domain rdf:resource="#Breaker" />
<rdfs:range rdf:resource="#ProtectionEquipment" />
<cims:inverseRoleName rdf:resource="#ProtectionEquipment.Operates" />
<cims:multiplicity rdf:resource="http://www.cim-logic.com/schema/990530#M:0..n" />
<rdfs:comment>"Circuit breakers may be operated by
protection relays."</rdfs:comment>
</rdf:Property>
<rdf:Property rdf:ID="ProtectionEquipment.Operates">
<rdfs:label xml:lang="en">Operates</rdfs:label>
<rdfs:domain rdf:resource="#ProtectionEquipment" />
<rdfs:range rdf:resource="#Breaker" />
<cims:inverseRoleName rdf:resource="#Breaker.OperatedBy" />
<cims:multiplicity rdf:resource="http://www.cim-logic.com/schema/990530#M:0..n" />
<rdfs:comment>"Circuit breakers may be operated by
protection relays."</rdfs:comment>
</rdf:Property>
EPRIは、様々なベンダ製品間で、実際の大規模なモデル(一つのテストの例では、2000以上の分局を記述するデータを使用)を交換するために CIM/XMLを使用して相互運用性のテストを行い、これらのモデルが一般のユーティリティアプリケーションで正常に解釈されることを確認した。CIMは、もともと、EMSシステムを目的としたものではないが、電力配信やその他のアプリケーションをサポートするように拡張できる。
オブジェクト管理グループ‐Object Management Group‐ は、オブジェクトインターフェース基準を採用してデータアクセス設備‐Data Access Facility [DAF]と呼ばれるCIM電力システムモデルにアクセスした。
CIM/XML言語と同様に、DAFはRDFモデルに準拠し、同じRDFS CIMスキーマを共有する。しかし、CIM/XMLは、モデルを文書として交換できるようにするが、DAFはアプリケーションがモデルにオブジェクトのセットとしてアクセスできるようにする。
CIM/XMLは、本来エンティティの関係やオブジェクト指向のクラス、属性、関係として 表現される情報(その情報が必ずしもWebでアクセスできる必要がなくても)のXMLベースの交換をサポートする際に、RDFが果たすことのできる便利な役割を説明する。この場合、RDFは、オブジェクトの認識や構造化された関係へのオブジェクトの使用をサポートする中で、XMLの基本の構造を提供する。この関係は、RDF(または、DAML+OILなどのオントロジー言語)とUML(とそのXML表現)との間の繋がりを調べる多くのプロジェクトと同様に、情報交換用のRDF/XMLを使用する多くのアプリケーションによって示している。
CIM/XMLへ濃度制約を追加する必要性によって説明された記述的な能力への必要性では、第5.5節に述べたDAML+OILやOWLなどのより強力なRDFベースのスキーマ/オントロジーの開発を導く要件の種類を示している。こういった言語は、将来の同じようなモデリングの応用をサポートする際に適切であるかもしれない。
最後に、CIM/XMLは、「現在のRDF」の例で見たようなものの重要な事実も示している。つまり、言語の中にはしばしば「XML」言語として記述されているものもある、とか、システムが「XML」を使用して記述されているか、そして、実際に使用している「XML」がRDF/XMLであるなど。これらはRDFアプリケーションである。これを理解するために言語やシステムの記述に進むことが必要な場合がある(いくつかの例では、RDFは全く明示的に述べられない例があるが、明確にRDF/XMLであると示しているサンプルデータもある)。さらに、CIM/XMLなどのアプリケーションでは、一般のアクセスではなくソフトウェアコンポーネント間での情報交換を目的としているので、作成されたRDFはWebで検索されない(しかし、将来のシナリオでは、この種のRDFがWebでアクセス可能になると想像できる)。
6.6 遺伝子オントロジーコンソーシアム
SNOMED RT (Systematized Nomenclature of
Medicine Reference Terminology) やMeSH (Medical Subject
Headings)などの制御されたボキャブラリを使用した構造化されたメタデータは、効率的な文献検索、医療知識[COWAN]の配信や交換を可能にし、医療で重要な役割を果たす。
同時に、医療分野の変化がめざましいため、更なるボキャブラリの開発が必要となる。
遺伝子オントロジー
(GO) コンソーシアムの目的は、制御されたボキャブラリを提供して遺伝子産物の特定な特徴を記述することである。データベースとの協業によって、参照とどの種類の証拠が利用できるかの記述の提供をし、遺伝子産物(または遺伝子)をGO用語で注釈をつける。これらのデータベースがこれらの共通のGO用語を使用することは、その用語での同一の照会を容易にする。GOオントロジーは、異なるレベルの細分性において、起因や照会を行うことができるように構造化されている。遺伝子と細胞内のたんぱく質の役割に関する知識は蓄積され、変化しているため、GOボキャブラリは動的である。
GOには三つの組織化原則がある。それは、分子機能、生物学的過程、そして、細胞成分である。遺伝子産物には、一つ以上の分子機能があり、一つ以上の生物学的過程で使用される。そして、一つ以上の細胞成分であるか、または、それに関連している場合もある。三つすべてのオントロジー用語の定義は、一つの(テキスト)定義ファイルに含まれている。XML (実際はRDF/XML)で形式化されたバージョンは、三つのオントロジーファイルと利用できる定義がすべて含まれており、すべて有効な定義であり、毎月作成される。
機能、過程、そして成分はDAG(方向付けられた非環式グラフ)または、ネットワークとして表現される。子用語は、その親用語の「インスタンス」(isa関係)、または、その親用語の構成要素(part-of関係)であることができる。子用語には、複数の親用語が存在することができ、異なる親との異なる関係のクラスを持つことができる。同義語と外部データベースとの相互参照もこのオントロジーで表現できる。幅広いツールのサポートとグラフ構造を表現する上での柔軟性のため、RDFはオントロジーのXML版で使用するために選ばれた。
例
36では、GO 文書からのGO情報のサンプルをいくつか紹介する。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE go:go>
<go:go xmlns:go="http://www.geneontology.org/xml-dtd/go.dtd#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<go:version timestamp="Wed May 9 23:55:02 2001" />
<rdf:RDF>
<go:term rdf:about="http://www.geneontology.org/go#GO:0003673">
<go:accession>GO:0003673</go:accession>
<go:name>Gene_Ontology</go:name>
<go:definition></go:definition>
</go:term>
<go:term rdf:about="http://www.geneontology.org/go#GO:0003674">
<go:accession>GO:0003674</go:accession>
<go:name>molecular_function</go:name>
<go:definition>The action characteristic of a gene product.</go:definition>
<go:part-of rdf:resource="http://www.geneontology.org/go#GO:0003673" />
<go:dbxref>
<go:database_symbol>go</go:database_symbol>
<go:reference>curators</go:reference>
</go:dbxref>
</go:term>
<go:term rdf:about="http://www.geneontology.org/go#GO:0016209">
<go:accession>GO:0016209</go:accession>
<go:name>antioxidant</go:name>
<go:definition></go:definition>
<go:isa rdf:resource="http://www.geneontology.org/go#GO:0003674" />
<go:association>
<go:evidence evidence_code="ISS">
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>fbrf0105495</go:reference>
</go:dbxref>
</go:evidence>
<go:gene_product>
<go:name>CG7217</go:name>
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>FBgn0038570</go:reference>
</go:dbxref>
</go:gene_product>
</go:association>
<go:association>
<go:evidence evidence_code="ISS">
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>fbrf0105495</go:reference>
</go:dbxref>
</go:evidence>
<go:gene_product>
<go:name>Jafrac1</go:name>
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>FBgn0040309</go:reference>
</go:dbxref>
</go:gene_product>
</go:association>
</go:term>
</rdf:RDF>
</go:go>
例
36では、go:termは基本の要素であると述べる。GOは、自身の拡張子をRDFボキャブラリ(RDFSを使用していない)に追加した。例えば、用語 GO:0016209には、<go:isa
rdf:resource="http://www.geneontology.org/go#GO:0003674" />がある。このタグは、関係「GO:0016209 isa GO:0003674」、または、英語で「Antioxidant is a molecular function.(酸化防止剤は、分子機能である)」と表現している。別の特化した関係は go:part-ofである。例えば、GO:0003674には、要素 <go:part-of
rdf:resource="http://www.geneontology.org/go#GO:0003673" />がる。これは、「分子機能は遺伝子オントロジーの一部である」という意味である。
注釈はすべて、文献参照、他のデータベース、または、コンピュータを利用した分析であるソースに帰属しなければいけない。注釈は、引用されたソースにどの種類の証拠が発見されたかということを述べて、遺伝子産物とGO用語の関係に対応しなければならない。簡単で制御されたボキャブラリが証拠を記録するために使用される。例には以下が含まれる。
- ISSは、「[<database:sequence_id>]と似ている結果から推測された」という意味である。
- IDAとは、「直接の検定から推測された」という意味である。
- TASとは、「著者の発言を突き止められる」という意味である。
go:dbxref要素は、外部のデータベースに表現し、go:association は、各用語の遺伝子関係を示す。go:associationには、関係に対応する証拠へのgo:dbxrefを持つgo:evidenceと、遺伝子のシンボルとgo:dbxrefを含むgo:gene_productの両方を持つことができる。
GOは、たくさんの興味深い点を示す。まず、情報交換のためのXMLの使用の値は、RDFを使用してそのXMLを構造化することによって強化できるということを示す。これは、厳密な階層ではなく、特にグラフやネットワーク構造を持つデータに当てはまる。GOは、(ファイルがWebでアクセスできても)Webでの直接使用にRDFが必ずしも存在する必要のない別の例でもある。もう一つの例では、表面的には、XMLとして記述されているのが、よく調べてみるとRDF/XMLであるというのがある。さらに、GOは、オントロジーを表現する基礎としてRDFが果たす役割を示している。この役割は、 第5.5節で示しているDAML+OILやOWLのようなオントロジーを指定するために、より豊富なRDFベースの言語に強化されると、より幅広く使用されるようになる。
近年、Webブラウジングを行うためのより多くのモバイル機器が出現している。これらの機器の多くは、幅広い入出力機能や異なるレベルの言語サポートなどを含む様々な機能がついている。 また、モバイル機器には、幅広く異なるネットワーク接続機能もついている。こういった新しい機器のユーザは、その機器の機能性や現在のネットワークの特徴に関係なく有効な表現を期待している。また、ユーザは、コンテンツやアプリケーションが表示される際(例えばラジオの電源の入切)に、動的に移り変わる嗜好を考慮してほしいと考える。しかし現実は、機器の異質性やユーザが自身の嗜好をサーバに伝える標準の方法が不足しているため、次のことが起こる。
コンテンツが機器に格納されない。コンテンツが表示されない、または、コンテンツがユーザの要望に違反する。など。さらに、結果としてコンテントがネットワーク経由でクライアントの機器に表示されるのに非常に時間がかかるということも起きる
この問題に対処するための解決策は、クライアントがその配送コンテンツ‐機器の機能、ユーザの嗜好、ネットワークの特徴など‐を、サーバがそのコンテキストを使用して機器やユーザ用にコンテンツをカスタマイズできる方法で、符号化することである (配送コンテンツについては、[DIPRINC]を参照のこと)。W3CのCC/PP(Composite Capabilities/Preferences Profile‐合成機能/嗜好プロファイル‐)使用 [CC/PP] は、配送コンテンツを記述するための一般的なフレームワークを定義することによって、この問題に対処する手助けとなる。
CC/PPフレームワークは、比較的簡単な構造‐コンポーネントと属性/値の一組の二つのレベルの階層ーを定義する。コンポーネントを使用して配送コンテンツの一部を捕らえることができる(例えば、ネットワークの特徴や機器がサポートしているソフトウェア、機器のハードウェアの特徴など)。コンポーネントには一つ以上の属性を含んでよい。例えば、ユーザの嗜好を符号化するコンポーネントには、AudioOutputが必要かどうかを指定するための属性を含んでもよい。
CC/PPは、RDFスキーマ(構造スキーマの詳細ついては[CC/PP]を参照のこと)を使用してその構造(上記の階層)を指定する。CC/PP ボキャブラリは、特定のコンポーネントとその属性を指定する。
しかし、[CC/PP]は、そういったボキャブラリを定義しない。代わりに、他の組織やアプリケーション(下記参照)でボキャブラリは定義される。また、 [CC/PP]
は、CC/PPボキャブラリのインスタンスをトランスポートするためのプロトコルも定義しない。
CC/PPボキャブラリのインスタンスをプロファイルという。CC/PP属性は、プロファイル内にRDFプロパティとして符号化される。例 37では、音声表現を好むユーザのユーザ嗜好に関するプロファイルのフラグメントを示す。
<ccpp:component>
<rdf:Description rdf:ID="UserPreferences">
<rdf:type rdf:resource="http://www.example.org/profiles/prefs/v1_0#UserPreferences"/>
<ex:AudioOutput>Yes</ex:AudioOutput>
<ex:Graphics>No</ex:Graphics>
<ex:Languages>
<rdf:Seq>
<rdf:li>en-cockney</rdf:li>
<rdf:li>en</rdf:li>
</rdf:Seq>
</ex:Languages>
</rdf:Description>
</ccpp:component>
RDFをこのアプリケーションに使用する利点がいくつかある。まず、CC/PPで符号化したプロファイルには、異なる組織で定義された属性を含むことができる。統合されたプロファイルデータのためのスーパースキーマを一つの組織が作成するわけではなので、RDFはこれらのプロファイルに自然に適合する。RDFの二番目の利点は、(グラフベースのデータモデルの効力で)任意の属性(RDF属性)のプロファイルへの挿入を容易にすると言うことである。これは、ロケーション情報など、頻繁に変化するデータを含むプロファイルに特に便利である。
オープン・モバイル・アライアンスは、プロファイルを運ぶためのプロトコルと同様に、ユーザエージェントプロファイル(UAProf)[UAPROF]
-デバイスの機能や、ユーザエージェントの機能、ネットワークの特徴などを記述するためのボキャブラリを含む[UAPROF]-CC/PPベースのフレームワーク-を指定している。UAProfは、HardwarePlatform、SoftwarePlatform、NetworkCharacteristicsとBrowserUABrowserUAを含む6つのコンポーネントを定義する。また、各コンポーネントの属性が決まっていなくても‐補足されたり、上書きされたり‐、各コンポーネントの属性をうちのいくつかを定義する。例
38では、HardwarePlatformコンポーネントのフラグメントを示している。
<prf:component>
<rdf:Description rdf:ID="HardwarePlatform">
<rdf:type rdf:resource="http://www.openmobilealliance.org/profiles/UAPROF/ccppschema-20021113#HardwarePlatform"/>
<prf:ScreenSizeChar>15x6</prf:ScreenSizeChar>
<prf:BitsPerPixel>2</prf:BitsPerPixel>
<prf:ColorCapable>No</prf:ColorCapable>
<prf:BluetoothProfile>
<rdf:Bag>
<rdf:li>headset</rdf:li>
<rdf:li>dialup</rdf:li>
<rdf:li>lanaccess</rdf:li>
</rdf:Bag>
</prf:BluetoothProfile>
</rdf:Description>
</prf:component>
UAProfプロトコルは、静的プロファイルと動的プロファイルに対応する。静的プロファイルは、URI経由でアクセスされる。これには、いくつかの長所がある。それは、サーバへのクライアントの要求には、URIのみ、もっと正確に言えば、かなり冗長になりかねないXML文書が含まれている(そのため、エアトラフィック最少げ限にする)ということ、クライアントはプロファイルを格納/作成する必要がないこと、そして、クライアントへの負担が比較的軽いと言うことである。動的プロファイルはオンザフライで作成され、結果的には関連するURIを持たない。
動的プロファイルは、静的プロファイルからの相違点を含むプロファイルフラグメントで構成されることがあるが、クライアントの静的プロファイルに含まれていない一意のデータを含むこともある。要求には、静的プロファイルと動的プロファイルがかなりたくさん含まれている。しかし、要求内では後からのプロファイルが古いプロファイルを上書きするのでプロファイルの順番は重要である。UAProfのプロトコルと複数のプロファイルの扱いについての規則の詳細は、[UAPROF]
を参照のこと。
他のコミュニティ(3GPPのTS 26.234 [3GPP] やWAPフォーラム・、マルチメディア・メッセージング・サービスクライアント・トランザクション・仕様-Forum Multimedia Messaging Service Client Transsactions Specification- [MMS-CTR]など)の中には、ボキャブラリをCC/PPを元に定義しているところもある。その結果、プロファイルはRDFの分散性質を利用し、さまざまなボキャブラリから定義されたコンポーネントを含むことができる。例
39 そういったプロファイルを示す。
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:prf="http://www.wapforum.org/profiles/UAPROF/ccppschema-20010330#"
xmlns:mms="http://www.wapforum.org/profiles/MMS/ccppschema-20010111#"
xmlns:pss="http://www.3gpp.org/profiles/PSS/ccppschema-YYYYMMDD#">
<rdf:Description rdf:ID="SomeDevice">
<prf:component>
<rdf:Description rdf:ID="Streaming">
<rdf:type rdf:resource="http://www.3gpp.org/profiles/PSS/ccppschema-PSS5#Streaming"/>
<pss:AudioChannels>Stereo</pss:AudioChannels>
<pss:VideoPreDecoderBufferSize>30720</pss:VideoPreDecoderBufferSize>
<pss:VideoInitialPostDecoderBufferingPeriod>0</pss:VideoInitialPostDecoderBufferingPeriod>
<pss:VideoDecodingByteRate>16000</pss:VideoDecodingByteRate>
</rdf:Description>
</prf:component>
<prf:component>
<rdf:Description rdf:ID="MmsCharacteristics">
<rdf:type rdf:resource="http://www.wapforum.org/profiles/MMS/ccppschema-20010111#Streaming"/>
<mms:MmsMaxMessageSize>2048</mms:MmsMaxMessageSize>
<mms:MmsMaxImageResolution>80x60</mms:MmsMaxImageResolution>
<mms:MmsVersion>2.0</mms:MmsVersion>
</rdf:Description>
</prf:component>
<prf:component>
<rdf:Description rdf:ID="PushCharacteristics">
<rdf:type rdf:resource="http://www.openmobilealliance.org/profiles/UAPROF/ccppschema-20010330#PushCharacteristics"/>
<prf:Push-MsgSize>1024</prf:Push-MsgSize>
<prf:Push-MaxPushReq>5</prf:Push-MaxPushReq>
<prf:Push-Accept>
<rdf:Bag>
<rdf:li>text/html</rdf:li>
<rdf:li>text/plain</rdf:li>
<rdf:li>image/gif</rdf:li>
</rdf:Bag>
</prf:Push-Accept>
</rdf:Description>
</prf:component>
</rdf:Description>
</rdf:RDF>
配送コンテキストとそのコンテキスト内のデータの定義は常に進歩している。そのため、RDF本来の拡張性とその結果の動的に変化するボキャブラリへのサポートをすることによって、RDFは、配送コンテキストの符号化のための適切なフレームワークとなる。
付録 A: URI(Uniform Resource Identifier)についての詳細
第2.1節のように、Web提供者は、Webでリソースを識別する(名づける)URI という識別子の一般的な形式を提供している。URLと違って、URIはネットワークロケーションのあるものやその他のコンピュータアクセス機構を持つものの識別に限定されていない。異なる数多くのURIスキーマ (URI形式) が様々な目的で開発され、使用されている。その例には以下がある。
- http: (Webページのハイパーテキスト転送プロトコル)
- mailto: (E-mailアドレス)例えば、 mailto:em@w3.orgなど。
- ftp: (ファイル転送プロトコル)
- urn: (場所的に独立した固定のリソース識別子となるのを目的としたURN)例えば、(本の)urn:isbn:0-520-02356-0など。
URIは RFC
2396 [URIS]で定義されている。
その他のURIに関しては、Naming and Addressing: URIs, URLs, ... [NAMEADDRESS]で参照できる。
現行のURLスキーマのリストは、Addressing Schemes [ADDRESS-SCHEMES]で参照できる。新しいものではなく、現行のスキーマの一つの採用を特別な識別目的で考慮するのはいいことである。
URIを誰が作成するのか、ということやURIがどのように使用されるかを誰もコントロールできない。URIのhttp:などのURIスキーマの中にはDSNなどの中心システムに依存しているが、freenet:などのその他のスキーマは完全に分散されている。つまり、URIの作成には特別な資格や許可は必要ないということである。また、自分が持っていないものを普通の言語で好きなように名前をつけて使用するのと同じ様に、自分が持っていないものに関してURIを作成することができる。
第2.1節で見たように、 RDFはURI参照 [URIS] を使用して、RDFステートメントで主語 (subject)、述語 (predicate)、目的語 (object) 、を名づける。URI参照(URIref)は、最後にフラグメント識別子URIを伴う。例えば、URI参照http://www.example.org/index.html#section2は、URIhttp://www.example.org/index.htmlと、('#’文字で区切られた)フラグメント識別子 Section2で構成されている。
URIrefは、絶対的にも相対的にもなれる。絶対URIrefが現れるコンテキストから独立したリソースを参照する。例えば、URIrefhttp://www.example.org/index.htmlなど。相対URIrefのプリフィックス(接頭辞)のいくつかが不足し、URIrefが現れるコンテキストからの情報で不足した情報を埋める必要がある場合の絶対URIrefの省略形である。例えば、相対URIrefotherpage.htmlはりソースhttp://www.example.org/index.htmlに現れる場合、絶対URIref http://www.example.org/otherpage.htmlに書きいれられる。URI部分がないURIrefは現行の文書(URIrefが現れる文書)への参照であると考えられる。そのため文書のURIrefが空白の場合、文書自身のURIrefと同じであると考えられる。フラグメント識別子だけで構成されるURIrefは、URIrefが現れる文書のフラグメント識別子が付加されたものと同じだと考えられる。例えば、http://www.example.org/index.html内にURIrefとして#section2 が現れる場合、絶対URIrefhttp://www.example.org/index.html#section2と同じだと考えられる。
[RDF-CONCEPTS]
では、RDFステートメントで主語 (subject)、述語 (predicate)、目的語 (object) (そして型付き(typed)リテラルではデータタイプ)などの相対URIrefを使用しないRDFグラフ(抽象的なモデル)はコンテキストで独立して識別されなければならないと述べている。しかし、RDF/XMLなど特定の具体的なRDFシンタックスは、ある場合では、相対URIrefが絶対URIrefの省略形として使用できるようにしている。本入門書のRDF/XMLのいくつかの例では、その使用法について述べている。詳細については、[RDF-SYNTAX] で参照のこと。
RDFとWebブラウザでは物事を識別するのにURIrefを使用しているが、RDFとWebブラウザではURIrefを少し違った方法で解釈している。なぜなら、RDFはURIrefを物事の識別のみ にしか使用していないが、ブラウザは物事の検索にも使用しているからである。違いが見られない場合の方が多いが、違いが顕著な場合もある。一つの大きな相違として、URIrefがブラウザで使用される場合は実際に検索できるリソースを識別すると予測されるということである。つまり、URIで識別される場所「の」リソースである、ということである。しかし、RDFでは、URIrefは人などのWebでは検索できない ものを識別するために使用される。URIrefがRDFリソースを識別するために使用される場合に、リソースについての記述的情報を含むページはそのURI「で」Webに配置されるという習慣でRDFが使用される場合がある。そのため、URIrefはその情報を検索するためにブラウザで使用できる。こういったことはある状況では便利なものであるかもしれないが、オリジナルのリソースとそれを記述しているWebページとを区別するのが難しくなる(この件についての詳細は、第2.3節で述べている)。 しかし、この習慣は明確なRDFの一部でななく、RDF自身、検索できるものをURIrefが識別していると想定はしない。
もう一つの違いがフラグメント識別子のあるURIrefの処理方法にある。URIで特定されている文書内の特定の場所を識別する場合、フラグメント識別子は、HTML文書を特定するURLにある場合がある。述べているリソースを検索するためにURI参照を使用する場合のHTMLの普通の使用法では、以下の二つのURIref、
http://www.example.org/index.html
http://www.example.org/index.html#Section2
が関連する(これらは二つとも同じ文書から参照され、二番目のURIrefは最初のURIrefの中の場所を特定する)。しかし、すでに述べたように、RDFはリソースを検索するのではなく純粋にリソースを 識別するために使用され、RDFは、これら二つのURIrefの特別な関係を想定はしない。 RDFが関わっている限り、構文的には異なるURI参照になるため、関係ないものを参照することがある(HTMLで定義した格納関係がないというわけではなく、RDFがURI参照のURI部分が同じであるという事実に基づいて存在する関係を想定しないということである)。
付録 B: XML(Extensible
Markup Language )の詳細
XML(Extensible Markup Language) [XML]は、誰もが自身の文書形式をデザインすることができ、その形式で文書を書くことができるようにデザインされた。HTML文書(Webページ)と同じように、XML文書には、テキストが含まれている。このテキストは、本来平易なテキストコンテンツとタグの形式のマークアップで構成されている。このマークアップを使用すると、処理プログラムが様々な構成の(要素)とよばれるコンテンツを解釈することができる。HTMLでは、許可できるタグとその解釈のセットがHTML仕様で定義されている。なお、XMLを使用するとユーザは自身専用の文書に採用している言語(タグとマークアップを表すことのできる構造)を定義することができる。例えば、以下はXMLベースのマークアップ言語を使用してマークアップされた簡単な一節である。
<sentence><person webid="http://example.com/#johnsmith">I</person>
just got a new pet <animal>dog</animal>.</sentence>
タグでで区切られている要素(<sentence>や<person>など)は、この一説に関わる特定な構造を反映するために導入されている。タグを使用すると、プログラムがこういった特定の要素を理解して書くことができ、構成されている方法で一説を適切に解釈できる。例えば、この例にある要素の一つ、<animal>dog</animal>の場合。これは、スタートタグ <animal>、要素コンテンツ、それと一致するエンドタグ </animal>で構成されている。person要素と共に、animal要素は、sentence要素のコンテンツの一部としてネストされている。以下の様な文章が作成される場合、ネスティングがよりわかり易い(この入門書のほかの部分にあるより「構造化」されたXMLのいくつかにもより近くなる)。
<sentence>
<person webid="http://example.com/#johnsmith">I</person>
just got a new pet
<animal>dog</animal>.
</sentence>
要素にコンテンツがない場合もある。要素は、<animal></animal>のように、スタートタグとエンドタグの一組でコンテンツを囲まないで書くこともできるし、<animal/>のように空の要素タグというタグの省略形を使用して書くこともできる。
スタートタグ(または空の要素タグ)には、タグ名以外の修飾情報が属性の形式で含まれていることがある。例えば、<person>要素のスタートタグには、(恐らく参照される特定の人を識別する)属性webid="http://example.com/#johnsmith" が含まれている。属性は、名前、等号記号、と(引用符で囲まれた)値で構成されている。
この特定のマークアプ言語は、要素の意味を伝達しようとする際に、用語「sentence」、「person」「animal」をタグ名として使用する。そして、英語を使用する人やこのボキャブラリを解釈する専用に書かれたプログラムにその意味を伝えるだろう。
しかし、もとからの意味はない。例えば、英語を使用しない人や、このマークアップを理解するようには作成されいないプログラムには、要素
<person>は全く意味をなさない。例えば、以下を例にとると、
<dfgre><reghh bjhbw="http://example.com/#johnsmith">I</reghh>
just got a new pet <yudis>dog</yudis>.</dfgre>
マシンにとっては、この一説は前述の例とまったく同じ構造であるが、タグは英語の単語ではないので英語を使用する人には、何を述べているががはっきりしない。さらに、マークアップ言語にはタグと同じ言葉が使用されるが、意図する意味とは全く違う場合がある。例えば、他のマークアップ言語の「sentence」は、犯罪者が刑罰に服する期間を意味する。そのため、XMLボキャブラリをストレートな意味で維持するためのメカニズムを提供しなければならない。
混乱を避けるため、マークアップ要素を一意に識別することが必要である。
XMLネーム空間 [XML-NS]をXMLで使用するとそれができる。
ネーム空間 とは、名前の特定の集合の修飾子としての役割をするWeb(空間)の一部を識別する方法のことである。ネーム空間は、ネーム空間のURIを作成することによって、XMLマークアップ言語用に作成される。ネーム空間のURIでタグ名を修飾することによって、誰もが独自のタグを作成し、他の人が作成した同等のスペリングでタグから区別できる。便利な方法として、Webページを作成しマークアップ言語(とタグの意図した意味)を記述しては、そのWebページをネーム空間のURIとして使用するということがある。以下の例では、XMLネーム空間の使用法について述べる。
<my:sentence xmlns:my="http://example.com/xml/documents/">
<my:person my:webid="http://example.com/#johnsmith">I</my:person>
just got a new pet <my:animal>dog</my:animal>.
</my:sentence>
この例では、属性xmlns:my="http://example.com/xml/documents/"が、XMLのこの部分での使用に対しネーム空間を宣言し、プリフィックス(接頭辞) myをネーム空間URI http://example.com/xml/documents/にマップする。そして、XMLコンテンツは、my:personなどの修飾された名前 (QNames)をタグとして使用できる。QNameには、コロンが後に続くネーム空間を識別するプリフィックス(接頭辞)と、XMLタグ、または属性名のローカル名 が含まれる。ネーム空間URIを使用して名前の特定なグループを区別することと、この例のようにネーム空間のURIでタグを修飾することによって、タグ名の衝突を気にしなくてもよい。同じスペルの二つのタグは、同じネーム空間URIを持つ場合にのみ、同じだと考えられるのである。
第2.1節で述べたように、RDFは特定のXMLマークアップ言語を定義する。これをRDF/XMLといい、詳細は第3節
に述べている。